


Today we're releasing a new benchmark for Speech-to-Text (STT) providers, focused on two dimensions that matter most for voice agents: transcription latency and semantic accuracy.
Our goal is specifically to evaluate STT performance for realtime voice agents. The best voice agents today can hear a user speak, transcribe their input, reason about a response, and begin generating audio in under a second. To hit that budget, every component in the pipeline needs to be fast. But speed alone isn't enough - the transcription also needs to be accurate enough that the LLM understands what the user actually said.
When a user speaks to a voice agent, three things matter:
- Semantic accuracy: The transcription doesn't need to be a perfect written record. It needs to convey the user's intent clearly enough for an LLM to respond correctly. This is more forgiving than traditional Word Error Rate (WER), because LLMs are extraordinary next-word predictors. They handle contractions, filler words, and minor grammatical variations without issue. What they can't handle is a wrong noun or a garbled name.
- Latency: A natural conversation has short pauses between turns. If your STT service takes over a second to finalize a transcript, you've burned most of the latency budget before the LLM even starts thinking.
- Turn detection: Has the user finished speaking? The most natural conversations emit transcripts quickly when a user's turn is finished, but give them time to think when they need it.
Existing STT benchmarks do a good job of measuring transcription accuracy, but voice agents require a different focus. Traditional WER penalizes "gonna" vs. "going to" as two errors - technically correct, but irrelevant when the transcript is being consumed by an LLM. And accuracy alone doesn't tell you whether a service is fast enough to keep a conversation feeling natural. We wanted a benchmark that evaluates both dimensions together, on real-world audio, through the lens of voice agent performance.
This benchmark focuses on accuracy and latency. Turn detection is a separate, complex topic that deserves its own treatment (we address it briefly below).
The source code for this benchmark is available on GitHub: https://github.com/pipecat-ai/stt-benchmark
Results
We benchmarked 10 STT services on 1,000 samples of real human speech. Here are the headline numbers:
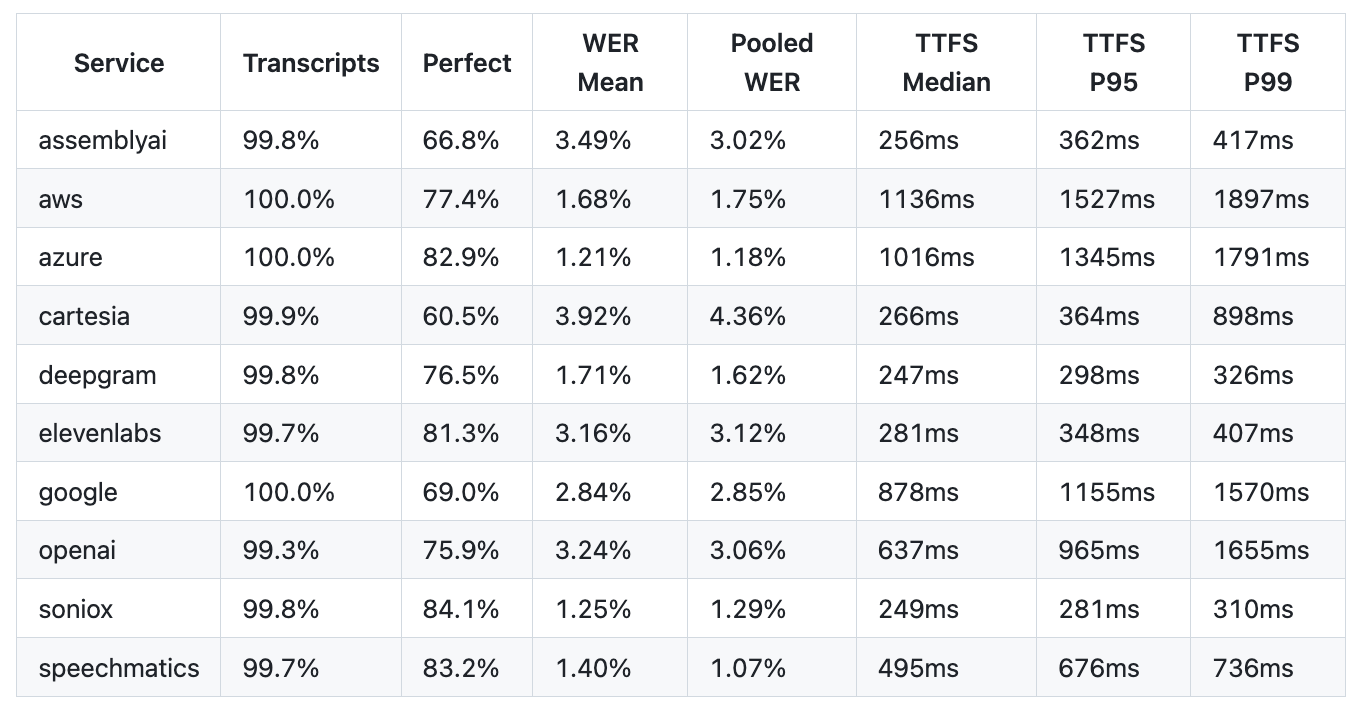
A few things stand out:
The STT space is heating up. As voice agents have grown in demand, STT providers have been investing heavily. There are now multiple excellent options delivering state-of-the-art performance on both accuracy and latency. A year ago, this table would have looked very different.
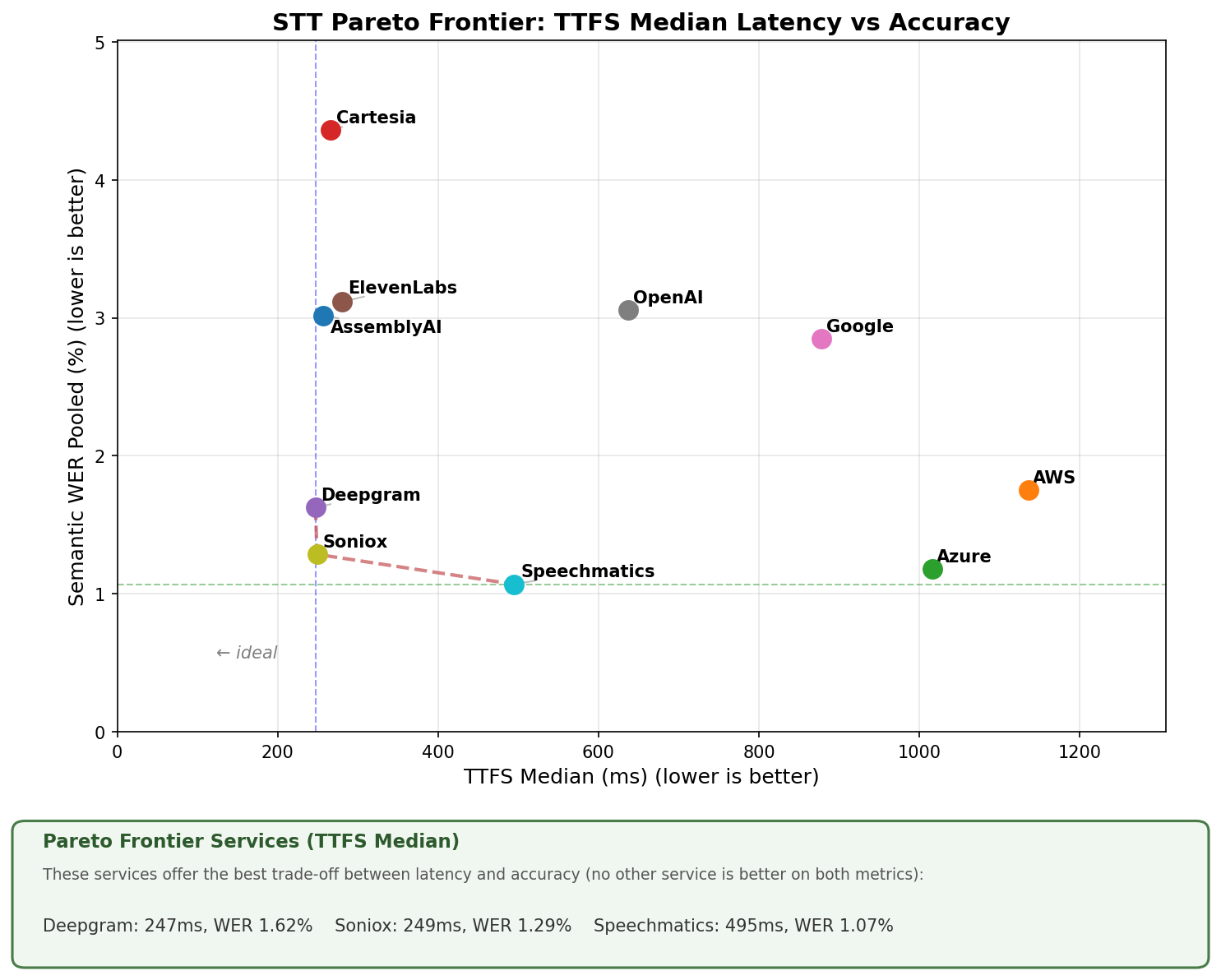
There's a clear latency-accuracy frontier. Some services are fast, some are accurate, and a handful manage to be both. The Pareto frontier below makes this trade-off visible:
Typical latency (Median TTFS)
Worst-case latency (P95 TTFS)
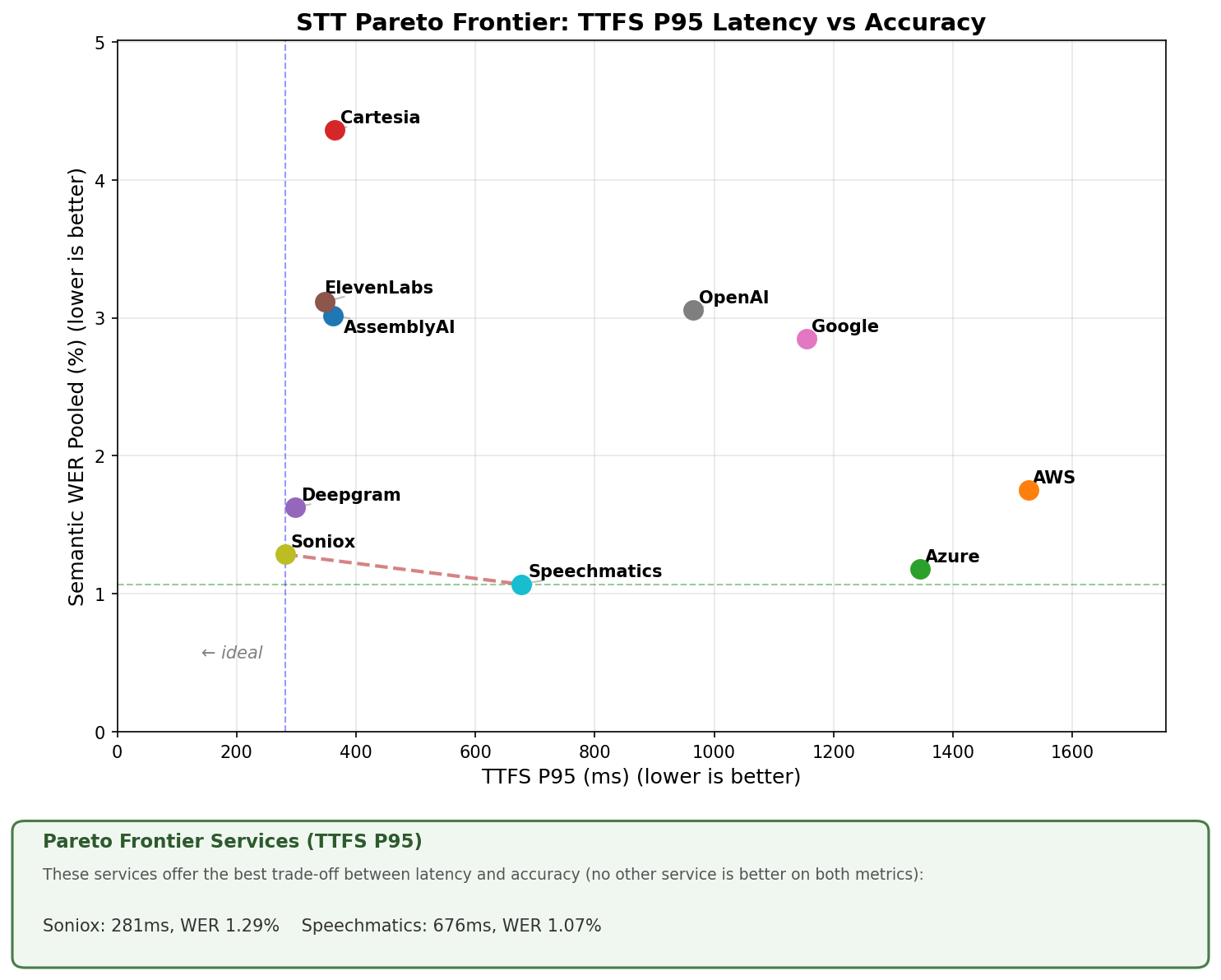
Services on the Pareto frontier offer the best trade-off between latency and accuracy. No other service is better on both metrics. The "ideal" corner is bottom-left: fastest and most accurate.
On median latency, three services sit on the frontier:
- Deepgram Nova 3 (247ms, 1.62% WER)
- Soniox (249ms, 1.29% WER)
- Speechmatics (495ms, 1.07% WER)
These represent different points on the speed-accuracy curve. But median latency only tells half the story.
Why P95 latency matters more than you think
When building voice agents, the input pipeline typically looks like this:

1. Transport: Receives streaming audio from the user, sends audio to the STT
2. STT: Transcribes speech in realtime, emitting partial and final transcripts
3. Context aggregator: Application code that collects transcripts and decides when a user has started and stops speaking
4. LLM: Perform inference to generate a response
There's a critical tension in step 3: you can't send transcripts to the LLM as they arrive. Streaming STT services emit multiple transcript segments over time. If you triggered an LLM completion on every partial or final transcript, you'd waste tokens and get responses based on incomplete input.
P95 tells you how long it will take the STT service to deliver a complete transcript, 95 times out of 100.
Median latency describes the average experience. P95 latency characterizes the worst-case experience. And in conversation, the worst cases are what users remember. A service with great median but poor P95 indicates inconsistent performance: usually fast, but occasionally slow enough to break the conversational flow.
A note on speech-to-speech models: new speech-to-speech models such as Ultravox, OpenAI Realtime, and Gemini Live simplify the voice agent pipeline by eliminating separate transcription and speech generation models. For a variety of reasons, almost all production voice agents today use the multi-model pipeline described above. For more on this, see the LLMs for voice agents open source benchmark, and the Voice AI Guide.
Finalization support is important
Some STT services support finalization, which means that we can send a signal to tell the service that the user has stopped speaking. The service then confirms the final transcript has been received with tokens or metadata in the transcription message, closing the loop with our application code. Given this finalization metadata, application code knows with certainty that the complete user input has been received, and can make an informed decision: proceed to LLM inference immediately, or defer to give the user more time to speak.
Services that support finalization don't require the application to wait an arbitrary amount of time, hoping that the STT service has completed processing. In practice, this means that for services that support finalization, the response time the user experiences will be approximately the median latency. But for services that do not support finalization, we have to wait longer to try to be sure we’ve gotten a complete transcript. We generally use the service’s P95 as a guide for how long to wait, and this means that every turn takes as long as the P95.
It's worth noting that the services with the lowest latency in our benchmark all support some form of finalization. When evaluating STT providers for voice agents, finalization support is worth considering alongside raw latency numbers.
That said, P95 still matters. It characterizes the upper bound of how long finalization itself takes. When evaluating STT for production voice agents, we recommend looking at P95 (or even P99) latency, not just medians. Your users experience both the average and tail of the latency distribution.
Semantic WER: Transcription accuracy for voice agents
Traditional Word Error Rate (WER) measures transcription accuracy by counting every word-level difference between a transcript and ground truth. "Gonna" versus "going to"? That's two errors. Missing a comma? Error. "3" instead of "three"? Error. This is a well-established metric that gives a clear, reproducible measure of transcription fidelity.
But in a voice agent pipeline, the transcript isn't the end product-it's input to an LLM. And LLMs are remarkably good at understanding natural language variations. Contractions, filler words, minor grammatical differences, number formats; an LLM handles all of these without issue. It will respond identically to "I'm gonna need 3 tickets" and "I am going to need three tickets." From the LLM's perspective, those are the same request.
This means many of the errors that traditional WER counts simply don't matter for voice agents. We need a different way to think about transcription accuracy. One that asks whether the LLM would understand the transcript correctly, not whether every word matches exactly.
Consider this example:
- Ground truth: "Can you describe the process for changing my legal name on official documents like my driver's license and social security card?"
- STT output: "Can you describe the process for changing my legal name on official documents like my driver licenses and social security card"
Traditional WER would flag multiple errors: "driver's" vs "driver", "license" vs "licenses", missing punctuation. But would an LLM respond any differently to these two inputs? No. Both clearly ask the same question. An LLM would understand both identically.
Now consider this:
- Ground truth: "I need to renew my prescription."
- STT output: "I need to review my prescription."
"Renew" to "review" - that's a real error. Both are plausible requests, but an LLM would take a completely different action for each. This is the kind of error that matters.
How Semantic WER works
We use Claude to perform multi-step semantic evaluation of each transcription. The process:
1. Normalize both texts: lowercase, expand contractions, normalize numbers, remove filler words, standardize spelling variations
2. Align the normalized texts word-by-word
3. Semantic check: For each difference, ask: *"Would an LLM agent respond differently to these two versions?"*
4. Count only the differences where the answer is yes
5. Calculate WER from the semantic error counts
The key question at step 3 is what makes this different from traditional WER. Here's how the semantic check works in practice:
Not errors (LLM would understand both the same way)

Real errors (LLM would misunderstand)

The evaluation prompt
The full evaluation uses a detailed system prompt with normalization rules, few-shot examples, and a structured calculate_wer tool that Claude calls after completing the analysis. Each evaluation produces a full reasoning trace that we store for auditability. You can inspect exactly *why* Claude counted or didn't count each difference.
We use claude-sonnet-4-5-20250929 for evaluation. The full prompt and tool definition are in the benchmark source code.
Pooled WER, mean WER, and perfect samples count
We report both:
- Mean WER: Average WER across all samples. Simple, but can be skewed by short samples where a single error produces a high percentage.
- Pooled WER: Total errors across all samples divided by total reference words. Weighted by sample length, so longer (harder) samples contribute proportionally more. Generally a more stable metric
- Perfect: How many of the input samples had perfect semantic WER scores
How the benchmark works
The pipeline
This benchmark is built on Pipecat, an open-source framework for building voice agents. Each benchmark run creates a Pipecat pipeline:
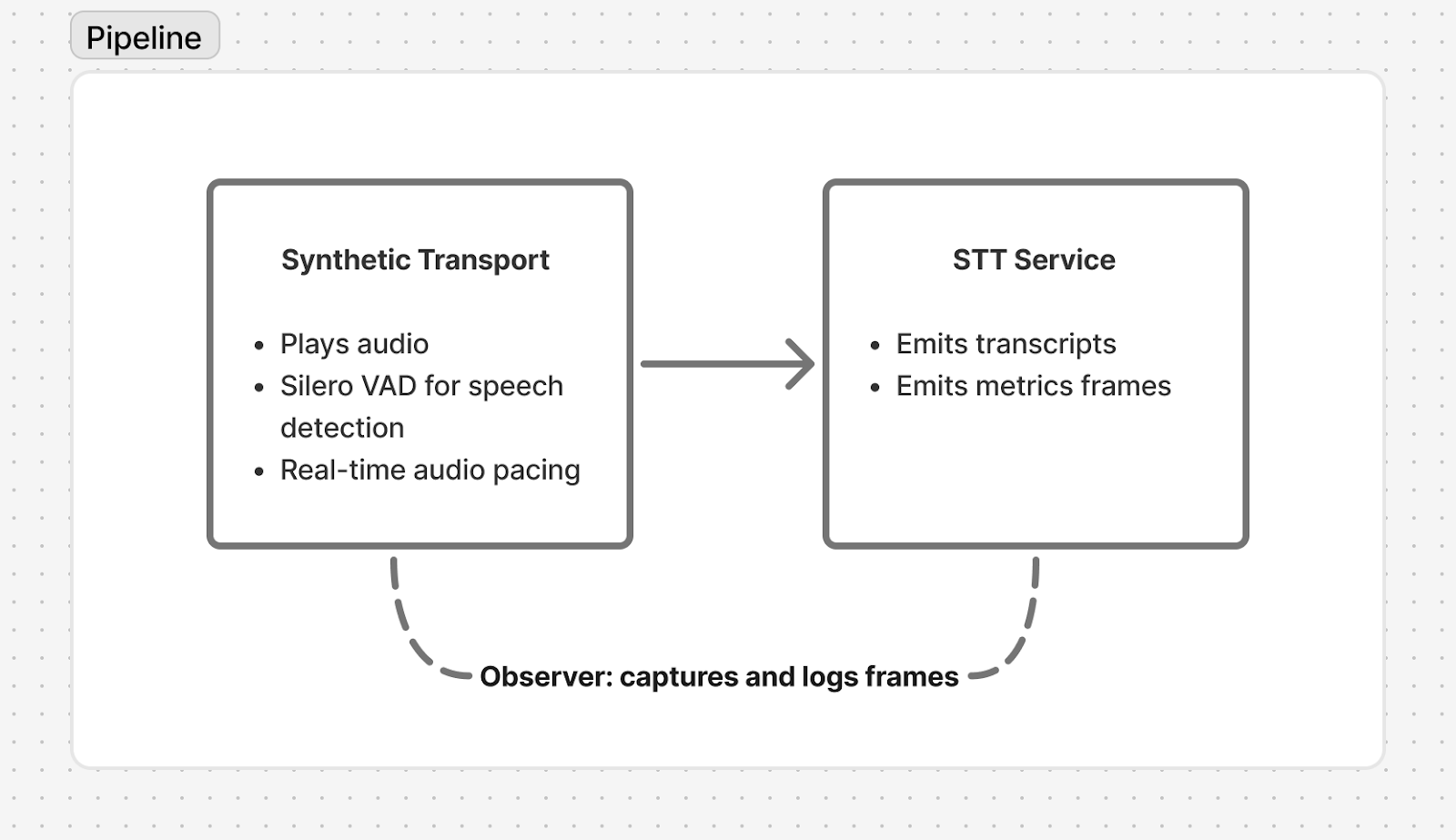
The Synthetic Transport plays pre-recorded PCM audio through the pipeline at realtime pace - 20ms chunks at 16kHz, exactly as a live microphone would deliver them. It uses Silero VAD to detect speech boundaries, emitting the same start/stop speaking events that a real transport would.
Each STT service processes the audio stream and emits transcription frames. Pipeline observers capture both the transcripts and timing metrics. After audio playback completes, the transport continues sending silence to give streaming services time to finalize their last segments.
This approach means every service sees exactly the same audio, delivered in exactly the same way, through the same pipeline infrastructure. The only variable is the STT service itself.
Measuring TTFS (Time To Final Segment)
For other services in a voice agent pipeline, like LLM and TTS, there’s a discrete input with a corresponding output, making latency straightforward to measure. Streaming STT works differently. User audio is continuously streamed to the STT provider:
This continuous stream can generate multiple transcription segments. Because we need the full transcription for the next stage in the pipeline (LLM inference), we measure from the last transcription segment received. We use this final transcript along with the VAD's stop-speaking event as two points in time to calculate a metric we call “time to final transcript,” (TTFS):
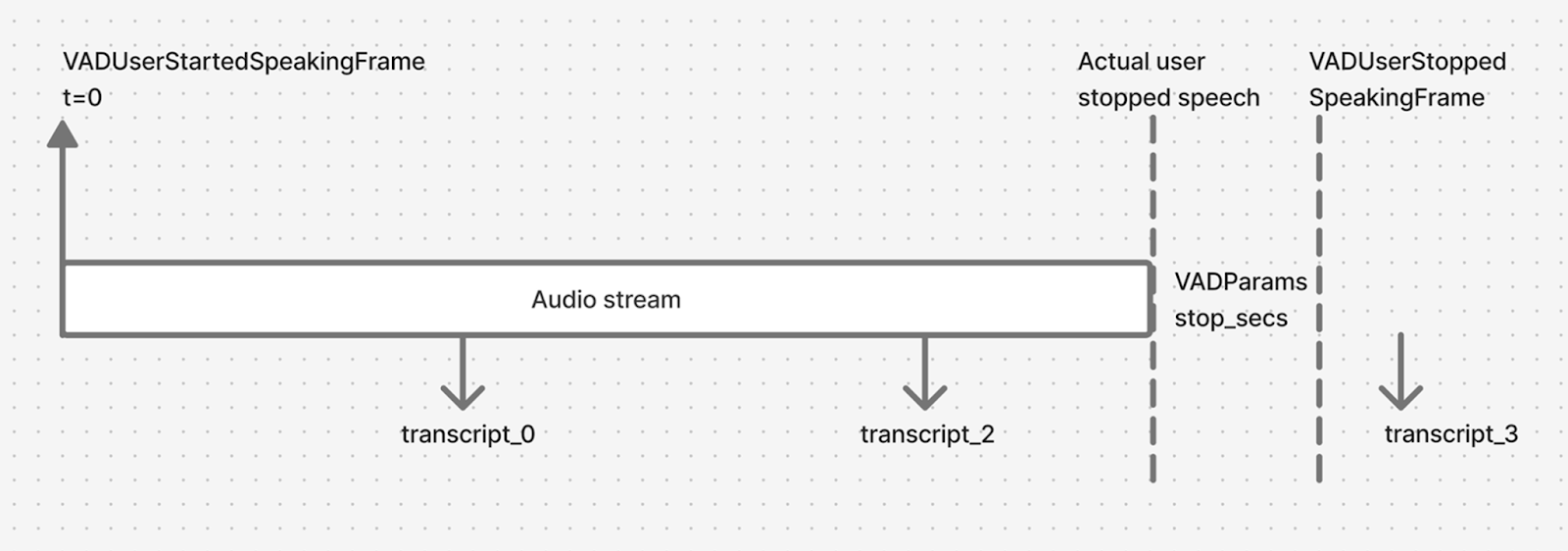
The time difference between the receipt of the last transcript and the time at which the user stopped speaking is the TTFS—the latency between the user’s final utterance and the last transcript from that utterance.
Data
All benchmark data comes from the pipecat-ai/smart-turn-data-v3.1-train dataset:
- 1,000 samples of real human speech
- PCM streaming audio at 16kHz mono
- English language only (for this benchmark)
- Real-world recording conditions: variable microphone quality, background noise, varying audio clarity. The goal is to represent what a voice agent actually hears in production, not laboratory conditions.
See the full data set and ground truth transcriptions:
https://huggingface.co/datasets/pipecat-ai/stt-benchmark-data
Ground truth
Ground truth transcriptions were generated in two passes:
1. Initial transcription by Gemini 2.5 Flash, with a prompt emphasizing literal, phonetic accuracy.
2. Human review and correction. Each transcription was reviewed with audio playback. Errors were corrected and the corrections tracked with an audit trail.
Service configuration
All STT services use their Pipecat integration. We worked with STT vendors to represent their best configuration for voice AI use cases. Key configuration choices:
- Smart formatting disabled where possible
- English language specified
- Latest models selected
- Endpoint locations closest to testing, which was performed in the US
All tests were run under similar conditions: US business hours on weekdays, from the same network location. While we can't fully control for provider-side load variations, running during consistent time windows helps minimize that noise.
A note on turn detection
We mentioned turn detection as the third critical component of the voice agent input pipeline. It's worth expanding on briefly, even though this benchmark doesn't measure it directly.
Turn detection answers: *"Is the user done speaking?"* Get it wrong in either direction and the experience suffers:
- Too aggressive: The agent cuts the user off mid-thought. They were just pausing to think, or taking a breath between clauses.
- Too conservative: Awkward silence. The user finished their sentence two seconds ago and the agent is still waiting.
Many STT services now include their own endpointing or turn detection signals. Examples include AssemblyAI, Deepgram’s Flux, Speechmatics, and Soniox.
In this benchmark, we use Silero VAD with a fixed stop threshold of 200ms for consistent TTFS measurement across services. In production, turn detection for these models can be enabled, or you can include a third-party model for turn detection. In the Pipecat ecosystem the Krisp VIVA turn detection model and the open source Smart Turn model are both widely used.
Turn detection is an active area of development, both at the STT service level and in the agent framework layer. We plan to address it in a future benchmark.
Caveats and limitations
All benchmarks carry bias. We've tried to be transparent about ours:
- English only: Results will differ significantly for other languages. Many of these services have strong multilingual support that we haven't tested here.
- Single dataset: The smart-turn dataset represents conversational voice agent input, but it's one distribution of audio. Enterprise telephony, accented speech, domain-specific terminology, and other conditions may produce different rankings.
- Configuration sensitivity: STT performance depends heavily on configuration. We worked with vendors to use recommended settings, but there may be configurations we missed that would improve specific services.
- Point-in-time: STT services update their models frequently. These results reflect a specific moment. We plan to re-run periodically and track changes.
- Semantic WER is a judgment call: Using an LLM to evaluate transcription accuracy introduces its own subjectivity. We've designed the evaluation prompt carefully with extensive few-shot examples, and we store full reasoning traces for auditability. But reasonable people (and models) could disagree on edge cases. We welcome feedback on our evaluation criteria - the full evaluation prompt is open source.
- Network conditions: Latency measurements are influenced by network path to each provider. We ran from a single US location. Results from other regions may vary.
Important takeaways
Building this benchmark reinforced a few things we already suspected, and surfaced a few surprises:
The accuracy floor has risen dramatically. Even the "worst" service in our benchmark (by WER) achieved a pooled Semantic WER under 4.4%. Every service transcribed successfully on 99%+ of samples. The days of unreliable STT are behind us for English conversational speech.
Latency varies greatly between services The gap between the fastest and slowest services is roughly 5x on median TTFS. For most voice agent applications, latency is so important that slow P95 times disqualify a service from consideration.
P95 latency reveals the real story. Several services that look competitive on median latency show significant tail latency. Building a reliable voice agent means planning for the P95 case, not the median case.
Semantic WER better reflects agent impact. Traditional WER would penalize many of these services more harshly. By focusing on errors that actually affect LLM understanding, we get a more useful picture of transcription quality for voice AI applications.
So which model should you use? There are three clear models on the Pareto frontier: Deepgram, Soniox, and Speechmatics. For many years, Deepgram was alone in delivering both accuracy and very low latency. Now there is significant competition. Competition is great for the voice AI ecosystem. It’s worth noting that there are other factors that influence model choice, beyond latency and WER:
- Performance in languages other than English, including the ability to do mixed-language transcription. This is an important area to cover in future benchmarks.
- Cost.
- The ability to run the model “on prem” or even on end-user devices. Self-hosting models (running "on prem") can improve latency significantly. Self-hosting is also a requirement for many enterprise use cases.
- Advanced features like turn detection and speaker diarization.
- The ability to customize or fine-tune a model.
We expect to see even more competition among transcription models, including along all of the axes listed above.
Try it yourself
The benchmark tool is open source:
https://github.com/pipecat-ai/stt-benchmark
An additional goal of this benchmark is to produce a utility that developers can use to measure the performance of their own STT service, configuration, and network location. We encourage you to run the TTFS portion of the benchmark to understand the latency characteristics specific to your setup.
The TTFS values from this benchmark directly inform how Pipecat configures its input pipeline. Starting in Pipecat 0.0.102, you can set the ttfs_p99_latency arg on your STT service to tell the context aggregator how long to wait for final transcripts. For services that do not support finalization signals, this lets your agent make better decisions about when to proceed to LLM inference versus waiting for additional transcript segments.
Never miss a story
Get the latest direct to your inbox.