


Daily powers real-time audio and video for millions of people all over the world. Our customers are developers who use our APIs and client SDKs to build audio and video features into applications and websites.
This week at Daily, we are writing about the infrastructure that underpins everything we do. This infrastructure is mostly invisible when it is working as intended. But it's critically important, and we're very proud of our infrastructure work.
Our kickoff post this week goes into more detail about what topics we’re diving into and how we think about our infrastructure’s “job to be done.” Feel free to click over and read that intro before (or after) reading this post.
Today, we'll describe Daily's Global Mesh Network. This is our distributed network of media servers that routes audio and video traffic scalably, securely, reliably, and at very low latency. Our wonderful teammate Chad, a Solutions Engineer here, also has shared a video walking through the ideas we're discussing today.

Thirteen ways of looking at a Global Mesh Network
Well, maybe not thirteen, but at least four …
Daily’s media servers are the most important part of our infrastructure. They route real-time audio and video traffic for the very wide variety of use cases we support: video calls, events, webinars, large interactive broadcasts, co-watching apps, audio spaces, metaverse environments, industrial robotics, and more.
We have media server clusters in 10 geographic regions and 30 network availability zones. This global coverage translates to a "first hop" network latency of 50ms or better for 5 billion people.
Why do we care so much about global coverage and first hop latency? In our kickoff post yesterday, we talked about the several perspectives we keep in mind as we aim to build the world’s best video and audio tech stack.
Briefly, this includes a focus on:
- The end-user experience (the experience of our customers’ customers),
- The developer experience (the design and ergonomics of our public APIs),
- Seeing the world through the lens of our experience as network engineers (you can’t cheat the speed of light, etc etc), and
- Bringing to bear our experience as video engineers (implementing storage systems and delivery networks for media and helping to write standards and specifications since the early days of video on the Internet).
Read on for some history, notes on our architecture from all of these perspectives, and thoughts about networking and the future of real-time audio and video:
- Delivering real-time video and audio
- How the Internet works and the challenges of delivering real-time video over unreliable networks
- WebRTC media servers (UDP and scaling sessions)
- Real time audio and video for real-time users
Delivering real-time audio and video
Daily's real-time audio and video capabilities are built on top of a standard called WebRTC. WebRTC is part of today’s web browsers and is widely used by applications like Google Meet and Facebook Messenger. WebRTC allows us to implement flexible video and audio services that interoperate across web pages, native mobile apps, and desktop applications.
WebRTC audio and video streams can be sent directly between two devices, or can be routed through media servers.
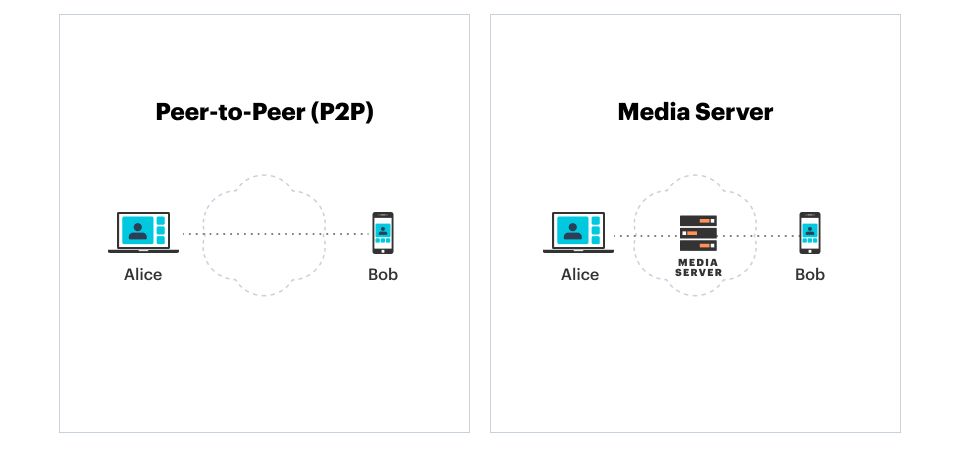
Direct connections, called peer-to-peer connections, have some advantages. Peer-to-peer can be less expensive for some use cases. Also, with peer-to-peer connections, provably secure end-to-end encryption is possible.
However, most video calls today are routed through media servers. This is true for the major WebRTC applications you are probably familiar with: Discord, WhatsApp, and Twitter spaces, for example. It's also true for Zoom, which has its own proprietary stack similar to WebRTC.
Using media servers is necessary to support more than a handful of participants in a call. Also, media servers will generally deliver better quality audio and video for participants who are far apart from each other geographically. So unless true end-to-end encryption is a hard requirement, it's preferable to route calls through media servers rather than use peer-to-peer routing.
Media servers are conceptually similar to the HTTP and Web Socket servers that most developers are familiar with. Each media server sends and receives data packets using standard Internet protocols. However, the specifics of how media servers work, the constraints that we optimize for when designing media server architectures, and, especially, how media servers work together, are quite different from the servers that most developers have experience with.
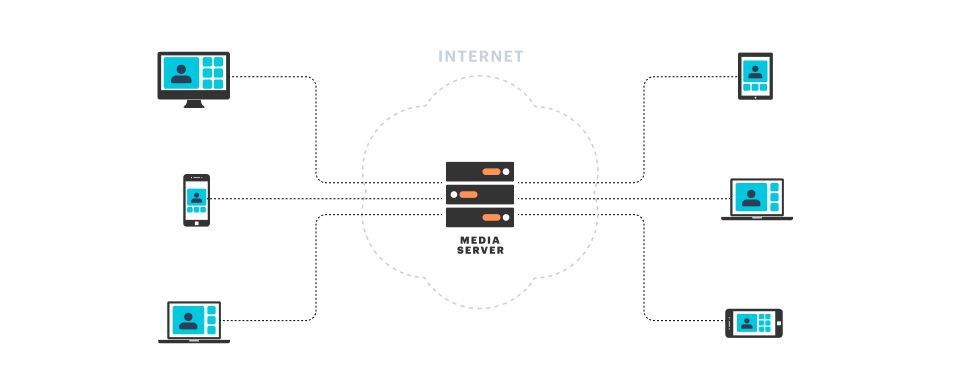
Our goals for Daily's media server infrastructure are to deliver audio and video:
- at the highest quality level possible for each connection, while
- scaling to support very large numbers of daily active users and large numbers of users in each session, and
- reliably in the face of Internet disruptions and cloud service provider outages.
How the Internet works, how real-time audio and video work, and the specific challenges of delivering audio and video over unreliable networks
A little bit of history
The Internet began in the 1960s as research into designing networks that could withstand faults and outages.
Early on, the Internet's new approach was controversial. The communications networks owned and operated by giant corporations like AT&T were "circuit-switched." The Internet's "packet-switched" architecture promised simpler, more open, more flexible, less expensive communications. But this new technology was unproven and the debate over circuits vs packets took many years to resolve.
Today, the Internet is everywhere, and everything is packets. Every time we download a web page, watch a YouTube video, or make a phone call, the data we send and receive is broken up into tiny fragments — data packets — and routed through multiple networks that cooperate to deliver the services we've come to take for granted.
Building reliability on top of unreliable links
Much of the technology that makes up the Internet is designed to achieve reliable communications on top of lower-level, unreliable network links.
On the Internet, any individual data packet could be lost in transit. So mechanisms to manage packet delivery are needed.
For example, the TCP protocol is used for most Internet traffic because it implements guaranteed in-order delivery of packets. HTTP — used for web pages and streaming video — is built on top of TCP. Web developers and programmers writing streaming video clients use TCP partly so that they don't need to worry about lost packets. Packet loss is always a problem on the Internet. But by using TCP, packet loss can be handled in a standard way at the protocol level.
However, real-time audio and video are very different from web pages, and even from streaming video. We have to manage packet loss in a different way.
Real-time requirements
(how humans process video and audio)
Humans find it natural to talk to each other. We talk face-to-face. We talk on the phone with just audio. And these days we often talk remotely via video. But we are highly sensitive to very small communication delays in a conversation. A phone or video call with a communication delay of more than about 200 milliseconds — one-fifth of a second — is a very unnatural experience.
This places an important constraint on real-time audio and video infrastructure. We need to keep network latency (the time it takes to deliver a data packet containing audio or video) to under 200 milliseconds whenever possible.
As a result, we don’t want to use TCP and its standard handling for lost packets. There's often not enough time to request that lost packets be resent. We have to be able to recover from lost packets gracefully, rather than assume that all packets will eventually arrive. Relatedly, any architecture choices we make that minimize packet loss are likely to pay big dividends. Finally, we know that whenever we can reliably improve the mean delivery time of packets and lower the delivery time variance, the subjective user experience benefits.
All of this informs how real-time media server architectures are designed.
WebRTC media servers
At a very high level, a media server is just a computer in the cloud and routes audio and video packets. But routing the right packets to the right clients, efficiently, and at potentially very large scale is an interesting problem!
How real-time audio and video work — enter UDP
An individual media server needs to be able to
- examine and forward large numbers of packets very quickly,
- adjust what data is sent to each client based on network conditions, and
- maintain state for each session and each connected device
As we talked about above, latency requirements for real-time audio and video are very tight. So, in general, media servers use the UDP Internet protocol instead of TCP. UDP is a simpler protocol that optimizes for faster, lower-overhead packet delivery.
The trade-off is that UDP doesn't maintain ordering of packets or handle packet retransmission.
So media servers cooperate with client-side code to do those two jobs. The media server maintains packet buffers and retransmits lost packets if there's time to do that. If not, the media server can facilitate graceful recovery from packet loss, for example by forwarding requests to restart a video encoding stream with a new keyframe.
Media servers also continually analyze the network to and from each client. If too much data is being sent to a client, the media server can turn off some tracks or can reduce the quality of one or more video streams.
Finally, media servers are the "source of truth" for clients about the state of a session.
All of this work turns out to be fairly CPU intensive. In a typical video call architecture, a media server might handle up to 500 or so simultaneous client connections.
Scaling to very large usage and large individual sessions
Obviously a popular application will have many more than 500 simultaneous active users. And, in fact, many use cases require far more than 500 participants together in one shared session.
Supporting large numbers of users requires horizontal scaling of media servers. When a new session starts, it is assigned to a server with available capacity. This is similar to how a horizontally scaling HTTP architecture might work.
Supporting large numbers of participants in a single session requires that media servers cooperate to host a session. There’s not really a very good analogy to this in the world of HTTP servers. The closest thing is probably handling sticky session state. For a video session, each client can connect to a different Daily media server. The servers together maintain a synchronized view of the session and route media as necessary from server to server and then to each connected client.
The “mesh” in Daily's Global Mesh Network
Server-to-server routing is the "mesh" that Daily's Global Mesh Network takes its name from. Every one of Daily's media servers is connected by a fast network connection to every other Daily media server, everywhere in the world.
This mesh topology is a flexible foundation for scaling. It also allows us to support a wide variety of use cases. Finally, this mesh network topology delivers particular benefits for sessions with participants in widely dispersed geographies.
Comparing mesh vs single-point routing
Shorter network routes are faster than long ones. (You can't argue with the speed of light, as network engineers sometimes say.) Sending data between people who are far apart takes a significant amount of time relative to the "latency budget" of a real-time conversation.
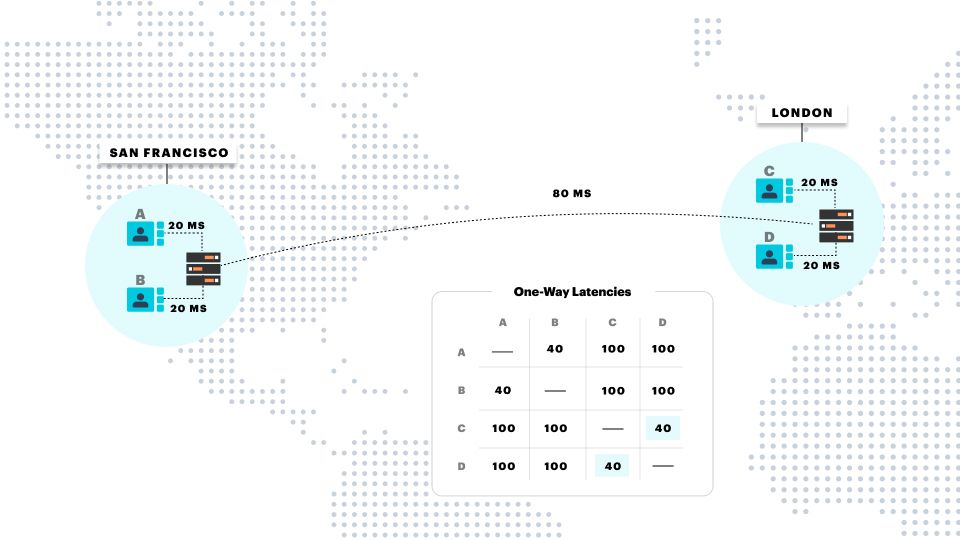
For example, the typical one-way latency on a good Internet route between London and San Francisco is about 80 milliseconds.
Remember that we'd like to keep the one-way latency below 200 milliseconds whenever possible. And now imagine that a media server is managing a real-time session for four participants, two in London and two in San Francisco.
Where is the best location for that media server?
This is a trick question! There's no good location for a single server that is hosting participants who are widely geographically dispersed.
In this example, if the server is in San Francisco, the audio and video sent between the two participants in London will have to cross the Atlantic Ocean twice. And if the server is in London, the San Francisco participants will have the same issue. We'll be using up almost all of our latency budget on those "hairpin" routes, even in a best-case scenario. And if any client's Internet route is below average, or there's any packet loss at all, the call experience is likely to be quite poor.
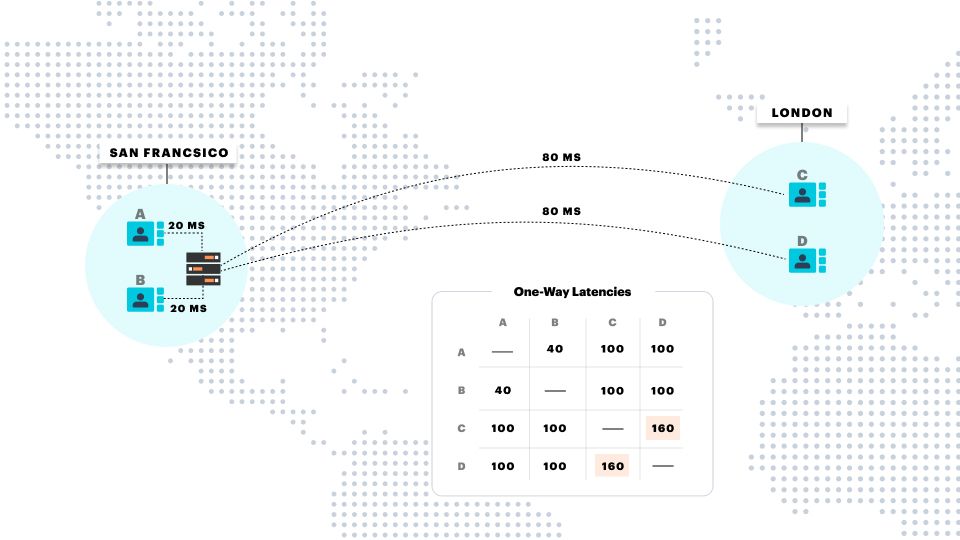
The solution is to use two media servers to host this call, one near San Francisco and one near London. This shortens the time as much as possible for all of the pair-wise transports between the participants.
Putting servers close to everyone in the world
We can further extend this insight that it's helpful for clients to connect to media servers that are close to them.
Connecting to a nearby server reduces latency to the media server itself and also reduces the variance of latency. Latency variance is called "jitter." A large amount of jitter forces a client to maintain a large "jitter buffer" — a memory buffer where incoming packets are queued so they can be assembled in order before being fed into audio and video decoding pipelines.
A larger jitter buffer translates directly to larger perceived delay in audio and video. Keeping jitter buffers as small as possible contributes significantly to a good user experience.
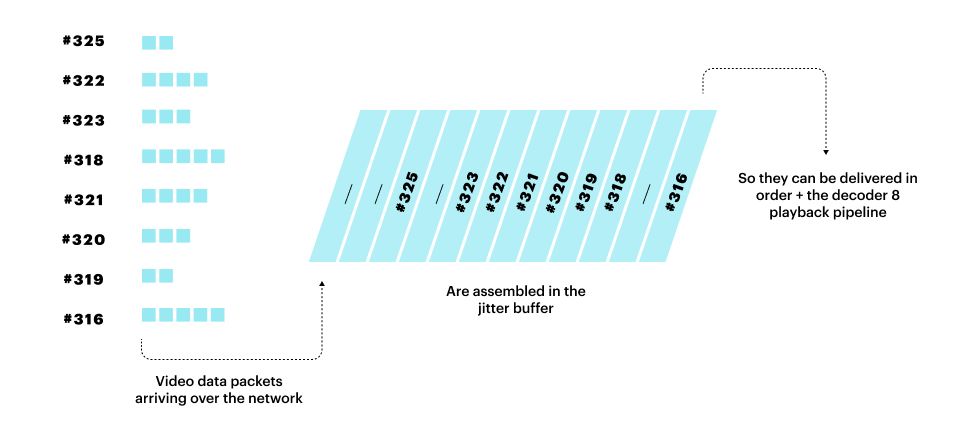
In addition, shorter network routes reduce packet loss and increase the chances that any lost packets can be resent within the tight timing of our latency budget. Lost packets impact video framerate and resolution. And, in the worst case, packet loss will cause audio quality to suffer as well.
Finally, Daily's media servers are connected by fast Internet backbone links, which are usually somewhat faster and significantly more reliable than long-distance routes across the open Internet. So it's often the case that adding an extra media server hop actually reduces the end-to-end latency between two clients that are far apart. This is a big reason that even for 1:1 sessions it's often better to use a media server than to use peer-to-peer connections.
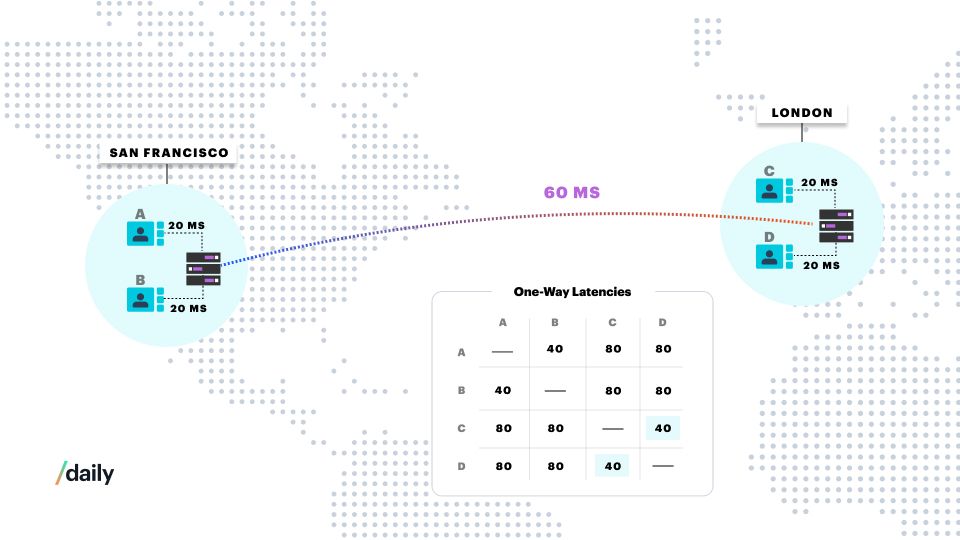
Adding all of this together means that it's extremely valuable to maintain clusters of media servers in data centers with excellent peering and connectivity close (in network terms) to as many users as possible.
Fault tolerance and routing around Internet issues
Finally, it's important for a media server architecture to respond quickly to faults and outages of various kinds.
An individual media server might disappear from the network or fail to accept new connections. An entire data center can become partly or completely inaccessible. A route between two data centers might drop.
For HTTP services, best practices around load balancing, observability, and failover are well known. Real-time video is a much less developed space and is perhaps even more complex. Many of the principles we use are similar to HTTP best practices, but some are new.
Daily's media servers all heart-beat basic health and service discovery state, and also push detailed performance information to our logging infrastructure. We have alarms and dashboards. Our autoscaling and failover logic is continually evolving. And over time we've improved our cost of service by optimizing both the media servers themselves and our capacity planning.
In addition, Daily's client libraries all push detailed performance and quality metrics to our big-data infrastructure during every session. With both server-side and client-side data available, we can explain the root causes for individual bad user experiences most of the time. And we can analyze data from billions of video minutes at the aggregate level to continually improve performance overall.
Real-time audio and video for real-world users
At Daily, our customers are developers and product teams. We care a lot about the ergonomics of our APIs and the overall developer experience when learning and using our SDKs.
However, writing code that implements audio and video features is just the beginning of the product journey. We've found that a very important part of our job is supporting our customers in supporting their customers.
From that perspective, call reliability and video and audio quality are the most important things we do. If calls don't work and users don't have a good experience, nothing else that we build will be very useful.
Or, put another way, we’ve seen empirically that reducing the "long tail" of user-impacting issues increases the growth and engagement for our customers' products.
Everything about our Global Mesh Network is built with our customers' customers in mind. Infrastructure that servers 5 billion people with 50ms or better latency. Fast backbone connections and mesh routing between media server clusters. Observability and debugging tools that show actionable insights about the user experience down to the level of individual sessions and participants. Support for 1,000 active participants and 100,000 passive participants at sub-200ms latencies.
Performant and flexible real-time platforms in the future will all need to implement something like Daily's Global Mesh Network. Software-defined networks and cascading media server capabilities are related approaches with similar goals. There is an evolving professional and academic literature on these topics.
The Global Mesh Network is our set of building blocks for the best video experiences in the world and the next generation of video-first applications.
Never miss a story
Get the latest direct to your inbox.