


We’re releasing a new version of our open source Smart Turn model, with improved inference speed, and support for multiple languages.
When used alongside a traditional voice activity detection (VAD) model, Smart Turn accurately detects when a speaker has finished their sentence, making use of semantic and vocal cues.
Smart Turn specifically uses the audio input (not just a text transcription) to the voice agent to perform the most accurate possible turn detection. The model outputs a prediction, indicating how likely it is that the user has finished speaking.
Using this information, an AI agent can avoid talking over a user, making conversations feel more natural and enjoyable.
We make everything about the model available as open source: the weights, the training script, and the datasets. Smart Turn is also integrated into the Pipecat framework.
- Model weights: https://huggingface.co/pipecat-ai/smart-turn-v2
- Code for training and inference: https://github.com/pipecat-ai/smart-turn
Native audio input
Smart Turn is trained on audio data and uses the speaker's audio as input. This allows us to make decisions using the intonation and pace of the user's speech — which provide essential cues about the user's intent — rather than just the words themselves.
Additionally, transcription models often ignore critical filler words like "um" and "hmm", whereas Smart Turn is explicitly trained to recognise these. As a result, the voice agent is able to perform the most accurate possible turn detection.
New features
- Support for 🇬🇧 🇺🇸 English, 🇫🇷 French, 🇩🇪 German, 🇪🇸 Spanish, 🇵🇹 Portuguese, 🇨🇳 Chinese, 🇯🇵 Japanese, 🇮🇳 Hindi, 🇮🇹 Italian, 🇰🇷 Korean, 🇳🇱 Dutch, 🇵🇱 Polish, 🇷🇺 Russian, and 🇹🇷 Turkish
- More than 6x smaller, weighing in at only 360MB compared to the previous model’s 2.3GB
- Inference is now 3x faster, with 12ms inference times on an NVIDIA L40S
Using the model
There are several ways to integrate Smart Turn v2 into your voice agent:
With Pipecat
Pipecat supports local inference using LocalSmartTurnAnalyzerV2 (available in v0.0.77), and also supports using the instance hosted on Fal using FalSmartTurnAnalyzer.
For more information, see the Pipecat documentation:
https://docs.pipecat.ai/server/utilities/smart-turn/smart-turn-overview
With Pipecat Cloud
Pipecat Cloud users can make use of Fal's hosted Smart Turn v2 inference using FalSmartTurnAnalyzer. This service is provided at no extra cost.
See the following page for details:
https://pipecat-cloud.mintlify.app/pipecat-in-production/smart-turn
With local inference
From the Smart Turn source repository, obtain the files model.py and inference.py. Import these files into your project and invoke the predict_endpoint() function with your audio. For an example, please see predict.py:
https://github.com/pipecat-ai/smart-turn/blob/main/predict.py
With Fal hosted inference
Fal provides a hosted Smart Turn endpoint which has been updated with the latest v2 model.
https://fal.ai/models/fal-ai/smart-turn/api
Please see the link above for documentation, or try the sample curl command below.
curl -X POST --url https://fal.run/fal-ai/smart-turn \
--header "Authorization: Key $FAL_KEY" \
--header "Content-Type: application/json" \
--data '{ "audio_url": "https://fal.media/files/panda/5-QaAOC32rB_hqWaVdqEH.mpga" }'
Accuracy
Smart Turn v2 achieves around 99% accuracy on unseen data from our human_5_all dataset, which contains English samples recorded by actual human speakers.
We also evaluate the model on synthetic data, broken down by language. The table below shows the approximate accuracy of the model when tested against unseen synthetic data.
| Language | Accuracy |
|---|---|
| 🇬🇧 🇺🇸 English | 94.27% |
| 🇮🇹 Italian | 94.37% |
| 🇫🇷 French | 95.46% |
| 🇪🇸 Spanish | 92.14% |
| 🇳🇱 Dutch | 96.72% |
| 🇷🇺 Russian | 93.02% |
| 🇩🇪 German | 95.79% |
| 🇨🇳 Chinese (Mandarin) | 87.20% |
| 🇰🇷 Korean | 95.51% |
| 🇵🇹 Portuguese | 95.50% |
| 🇹🇷 Turkish | 96.80% |
| 🇯🇵 Japanese | 95.38% |
| 🇵🇱 Polish | 94.57% |
| 🇮🇳 Hindi | 91.20% |
In this case, accuracy is defined as the percentage of times when the model correctly classified a sample as either “complete” or “incomplete”, with a 50/50 split of input samples of each type.
We suspect that the main thing holding back the accuracy is invalid or ambiguous samples in the dataset. Manually cleaning up the human_5_all dataset took us from 95% accuracy up to 99%, and so we’re planning to do the same for our new chirp3_1 dataset.
Performance
Smart Turn v2 is around three times as fast as the first version. We've included some approximate benchmarks below showing the performance of the model on various devices, when processing 8 seconds of input audio.
| Device | Inference time |
|---|---|
| NVIDIA L40S (Modal) | 12.5 ms |
| NVIDIA A100 (Modal) | 19.1 ms |
| NVIDIA L4 (Modal) | 30.8 ms |
| NVIDIA T4 (AWS g4dn.xlarge) | 74.5 ms |
| CPU (Modal) | 410.1 ms |
| CPU (AWS c7a.2xlarge) | 450.6 ms |
| CPU (AWS t3.2xlarge) | 900.4 ms |
| CPU (AWS c8g.2xlarge) | 903.1 ms |
| CPU (AWS c8g.medium) | 6272.4 ms |
Architecture
For the first version of Smart Turn, we opted to base the model on wav2vec2-BERT, in the hope that BERT’s pretraining on 4.5 million hours of multilingual data would help us generalize turn detection to multiple languages.
In practice, during the training of our v2 model, we found that wav2vec2-BERT actually gives less accurate results on unseen data than wav2vec2, possibly because of overfitting with the larger model.
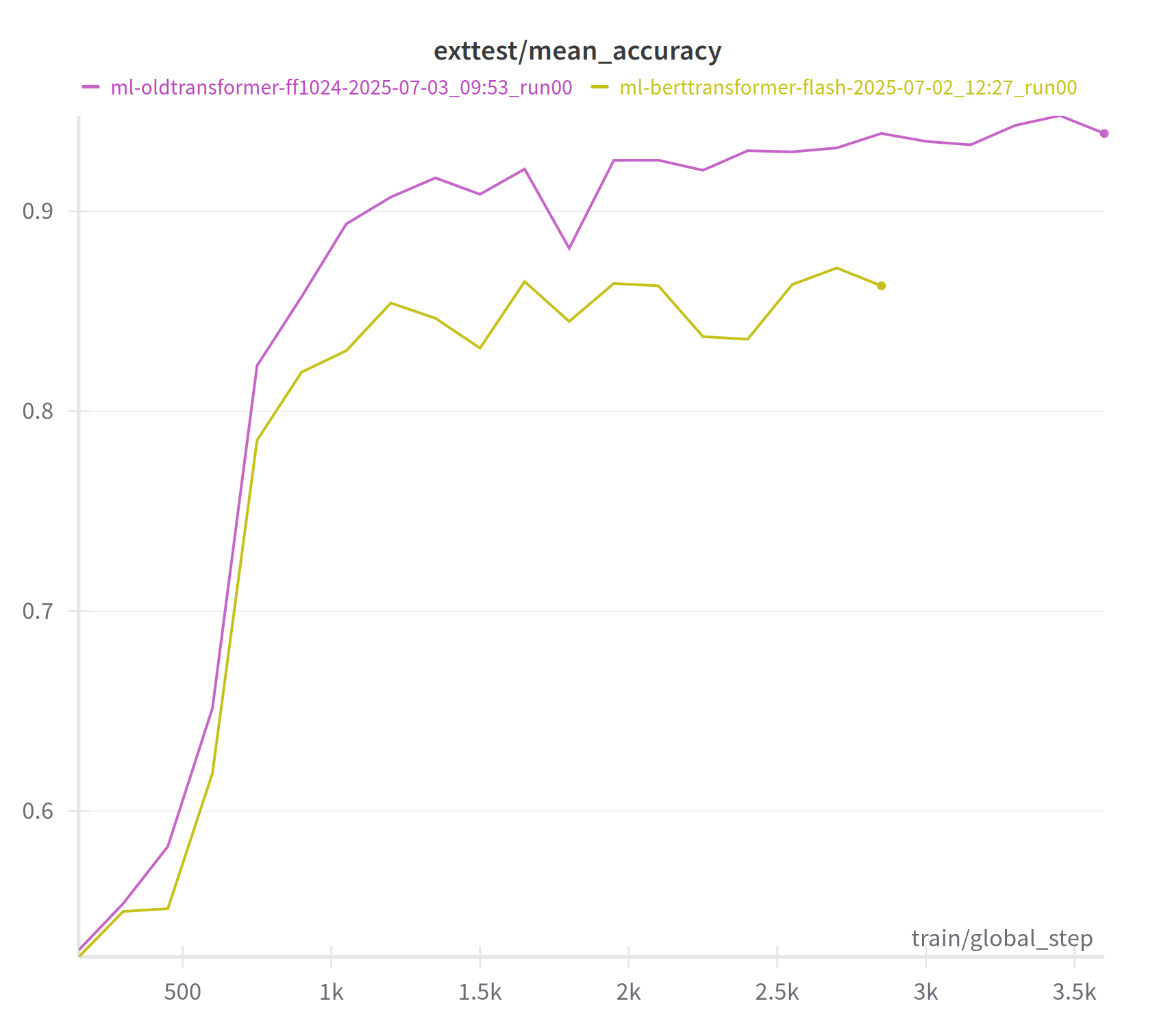
We experimented with several different architectures, including LSTM-based models, and also models where we appended some extra transformer classifier layers to the end of wav2vec2. So far, the best performing architecture we’ve found has been wav2vec2 with a linear classifier.
We’ll continue investigating how we can improve the model’s performance in future, and it’s likely that even smaller versions of the model will continue to produce accurate results.
Dataset
Until now, Smart Turn has only been trained on English datasets, and for this new multilingual version, we’ve added samples in 13 additional languages.
Our goal has always been to rely on synthetic training data as much as possible, because it allows us to generate a much higher number of samples at a lower cost. This means the audio samples are generated using a TTS model, rather than recorded by a human.
All the datasets used to train Smart Turn are freely available here: https://huggingface.co/pipecat-ai/datasets
Text to speech
There are two main types of incomplete sentence we want the model to detect:
- Those ending in a filler word, for example, “My phone number is, um…”
- Sentences where the speaker uses intonation and vocal cues to indicate that they have more to say
Many text to speech models perform poorly in both these cases. In our testing, few seem to be capable of ending a partial sentence with the desired intonation, and often, filler words like “um” and “er” are pronounced in an unnatural way.
We eventually settled on Google’s Chirp3 model. Pronunciation of filler words is excellent, and we found that ending a sentence with a comma generally causes the model to use the correct intonation.
Sentence list
We used the following dataset as a starting point, as it contains a large number of textual sentences in a variety of languages:
https://huggingface.co/datasets/agentlans/high-quality-multilingual-sentences
Despite the name, we found that not all of the sentences in the dataset were high quality. Many of them were grammatically incorrect, incomplete, or they resembled article section headers rather than something a person would speak out loud.
{"text": "HOW TO GET YOUR There is two ways to get them."}
{"text": "ALGOL and programming language research As Peter Landin noted, ALGOL was the first language to combine seamlessly imperative effects with the lambda calculus."}
{"text": "Etymology The word aesthetic is derived from the Ancient Greek , which in turn comes from and is related to ."}
To clean up the data, we used the Gemini 2.5 Flash LLM, asking it to classify each sentence as follows:
Please look at the following sentence, and place it in one of the following categories:
G: The sentence is ungrammatical
P: The punctuation is invalid
I: It is grammatically or semantically incomplete
S: It is unlikely to appear in spoken text (as opposed to written text, e.g. a section header)
C: It mentions controversial topics such as politics or religion
L: The sentence does not match the expected language
X: It doesn't fall into any of the above categoriesProvide a brief rationale in at most 10 words, and then give your classification in the form @X@ (with an "at" symbol on each side).
Depending on the language, around 50-80% of the sentences were thrown away.
Filler words
Each language has a different set of filler words. Whereas someone speaking English might fill in a gap with “um…”, someone speaking Japanese might use “えーと” or “あの”.
Using Claude and GPT-o3, we built up a list of filler words in each language. We also included various connective words such as “and”, “but”, and “so”, because these will almost never end a sentence and would imply the speaker has more to say.
For previous English datasets, we were able to split the sentence randomly at a space, end the sentence there, and append a random filler word. This time, we used an LLM (Gemini Flash). This allows us to handle languages which don’t use spaces to separate words, such as Chinese, and also allows us to split the sentence at a more natural point.
Take this sentence and cut it off near the end, then add the filler word "{filler}" and ellipses (...) at the end.
For example:
- "How tall is the Eiffel Tower" → "How tall is the, um..."
- "What time does the store close" → "What time does the store, uh..."
Sentence to process: "{sentence}"
Filler word to use: "{filler}"Think about where to cut the sentence naturally (as close to the end as possible), then provide your final answer wrapped in @@@ symbols like this: @@@Your incomplete sentence here@@@
We also generated subsets of data which had filler words in the middle of the sentence, to teach the model to distinguish between the two cases — just because someone said “um” halfway through their sentence, it doesn’t mean they didn’t finish talking.
Training runs
We use Modal to perform model training. For this new version, we switched to an L40S GPU, and also modified the training script to make use of more CPU cores and system memory (to speed up dataset processing).
@app.function(
image=image,
gpu="L40S",
memory=16384,
cpu=16.0,
volumes={"/data": volume},
timeout=86400,
secrets=[modal.Secret.from_name("wandb-secret")],
)
def training_run(run_number):
Evaluation
We log evaluation results to Weights & Biases live during each training run, which lets us observe how the accuracy of the model evolves as each run progresses.
The training script breaks down the evaluation data by language, so that we can see the performance of each language individually.
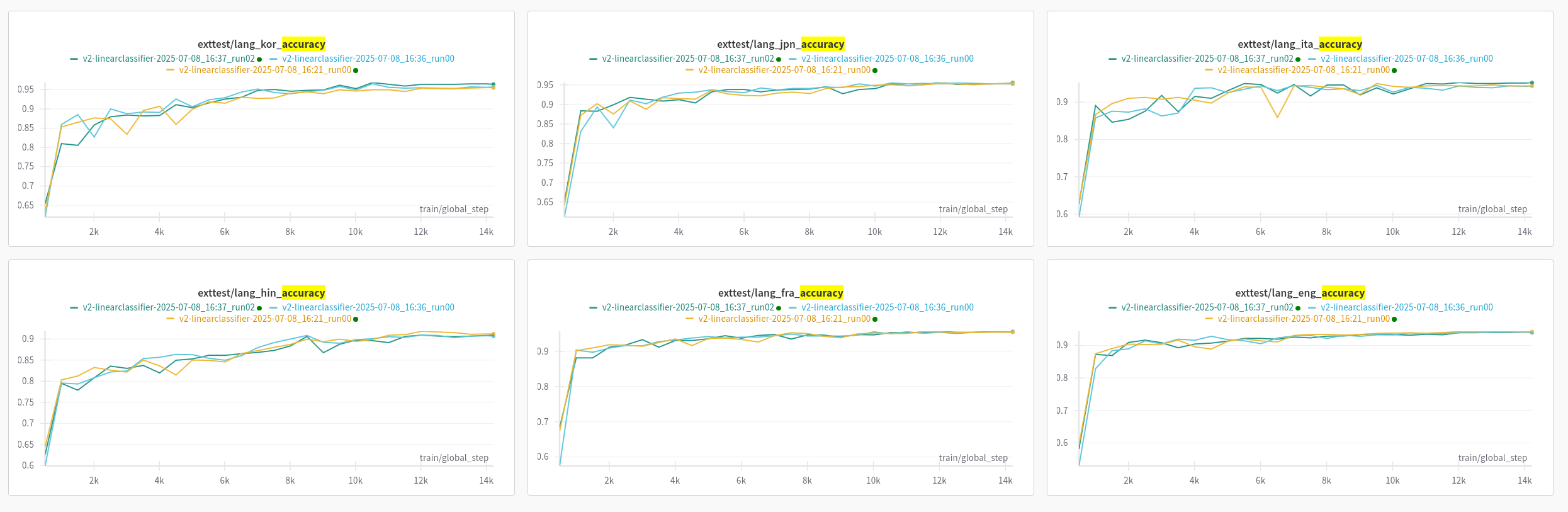
We keep the training and evaluation data separate, to ensure that the model can handle inputs that weren’t in its training set. On average, we see around 95% accuracy on this unseen training data.
Help needed: Cleaning up the dataset
As the dataset is synthetic, some of the samples are inaccurate or sound unnatural. To combat this, we’re aiming to manually verify and classify each of the generated samples.
Anyone can help out with this effort, which will improve the accuracy of the next generation of Smart Turn models.
https://smart-turn-dataset.pipecat.ai/
Help needed: Contributing human data samples
Data samples contributed by people (as opposed to synthetic data samples) are essential for evaluating the model and also for training. If you’d like to contribute to this, please visit the following link:
https://conversation-collector.vercel.app/
Conclusion
We’d love to hear your thoughts on the new model — you can get in touch with us at the Pipecat Discord server or on our GitHub repo.
We hope the new multilingual version will open up Smart Turn to more users and use cases, and we look forward to adding even more languages in future!
Never miss a story
Get the latest direct to your inbox.