

In this post, we will talk about how we have thought about the live streaming and recording features here at Daily, particularly from the lens of having a robust, scalable architecture. Most of this post should be beginner-friendly, but we might end up seeing some acronyms more familiar to the hard-boiled multimedia folks in the audience. We’ll be sure to link to relevant resources as we come across them.
Feature overview
As a quick refresher, the Daily API provides methods to stream an on-going call to an external service, such as Amazon IVS, YouTube, Facebook, or any service that can ingest audio and video via RTMP.
It is also possible to record a call with Daily's APIs. We store these recordings in Amazon’s Simple Storage Service (S3), encrypted at rest, and provide customers with access to these recordings on our dashboard or via our REST API.
One way to look at recordings is as a special case of streaming – that is to say, instead of streaming to an external server using a protocol like RTMP, we are streaming the data to an S3 bucket to store for later use. For the rest of this post, we will use “streaming” as shorthand for “streaming or recording”.
How do you stream a call?
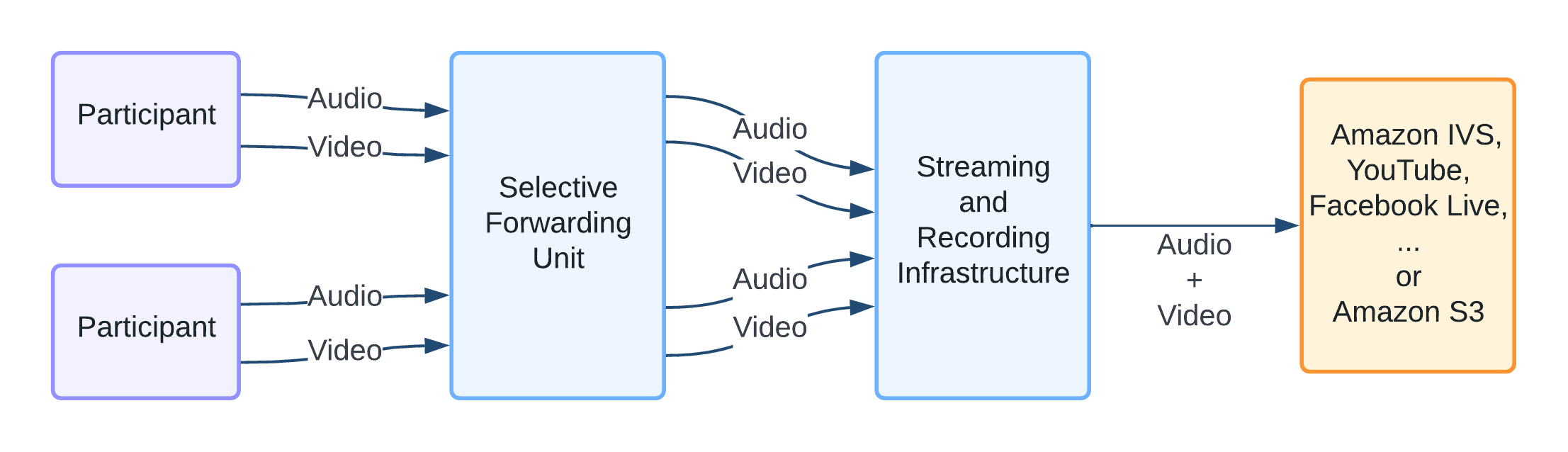
As we write in our video call architecture documentation, participants in a call stream audio and video to each other directly (P2P) or via an intermediate infrastructure (the SFU).
For the purposes of streaming a call, we need to combine the audio and video streams from all the participants into a single stream of audio and video. To do this, we must first receive all the streams (i.e. the call must be in SFU mode). We use a modified version of the mediasoup SFU in our backend, and this includes some handy mechanisms to forward audio and video streams sent by participants to an external entity as an RTP stream (this is more or less what the participants themselves send to the SFU).
We then combine video streams by “compositing” them together in one of our many supported layouts to form a single video output. We also mix audio streams together to form a single audio output.
With a single output audio and video stream, we can now multiplex (“mux” in multimedia nerd parlance) the audio and video into a single stream, typically, using a common container format such as MP4 for recordings, or FLV for RTMP), and then stream them to the appropriate service.
Visually, this might look something like:
Architecture choices
Before we talk about how we built this feature out, let’s talk about how we didn’t.
A common approach to building streaming and recording on top of an SFU architecture is to consume these streams in a headless browser (usually Chrome) in the cloud. This headless browser acts as another hidden participant in the call, consumes the streams it wants to capture, and composites them to its HTML canvas like it would any website. Audio can similarly also be mixed using standard web primitives. The output may then be captured and streamed from within the browser JS code, or an outside process running within the same instance. This is the equivalent of doing a screen capture/recording.
The advantages of this approach are clear: browsers provide a powerful runtime (JavaScript) for arbitrary tasks, and the ability to run a similar codebase to the in-browser call experience provides a quick path to shipping a reasonably feature-rich streaming experience.
There is, however, an important downside to this approach, which is scalability. Browsers being a feature-rich, general-purpose runtime and canvas means that they also require computational resources to do their job.
Custom compositor
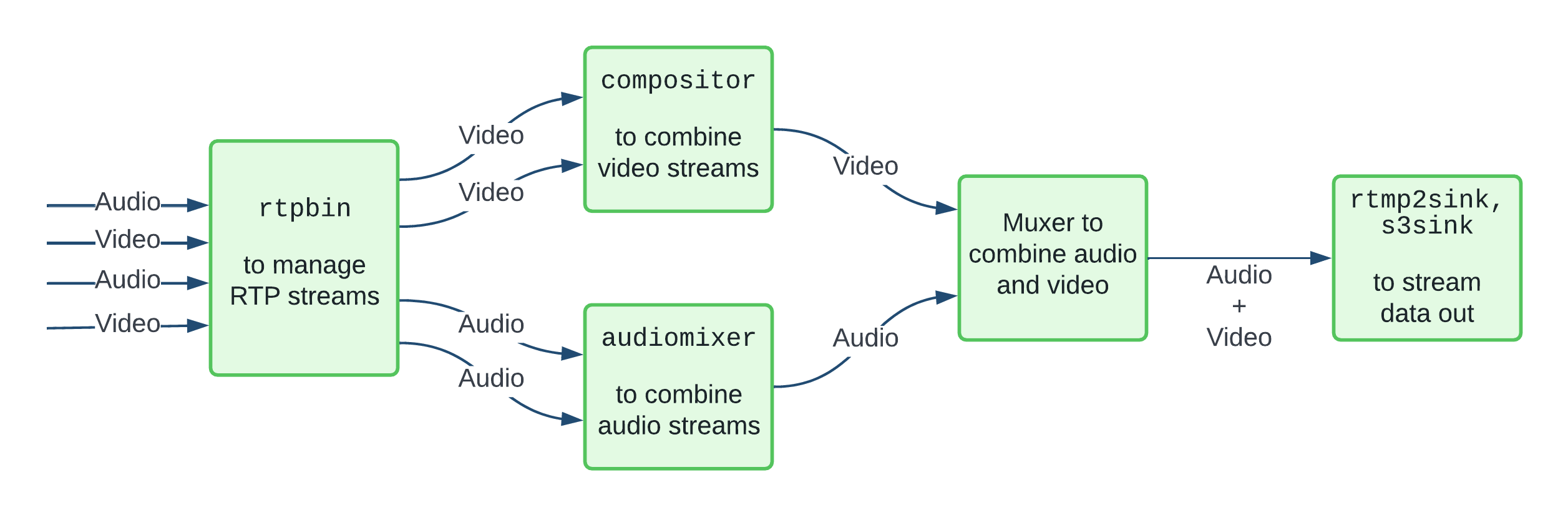
Our streaming infrastructure runs a custom application using the GStreamer multimedia framework to consume RTP streams from mediasoup and composite, mix, and stream them. GStreamer gives us a flexible set of building blocks to perform each of the steps we need:
- Consume media streams over RTP (with all the bells and whistles to handle jitter, RTCP feedback for packet loss, etc.)
- Decode these streams
- Composite raw video and mix raw audio streams
- Encode audio and video (as AAC and H.264 for now)
- Mux audio and video (as MP4 for recordings, FLV for RTMP, potentially other formats depending on the output)
- Stream to the chosen output (RTMP or S3, for now)
A simplified version of our GStreamer pipeline might look something like this:
While recording a call, we “stream” the multiplexed recording to S3 as a multipart upload rather than store the recording locally and upload at the end of the call – this is all relatively straightforward using the GStreamer S3 plugin.
We found that GStreamer ships the functionality we need in most of these cases, and we were easily able to add additional features or build new plugins as needed. We are even happy to have some of this work upstream.
With this architecture, we are able to think of our backend in terms of what it truly is: namely a media pipeline. We are able to quickly extend it for new uses: we added support for multiple RTMP outputs in a couple of days, and astute readers will see other new upcoming features hidden in the links above.
Into the future
Our current implementation offers a few layout options that are commonly used in live streams and recordings. This includes a typical grid layout, an “active participant” mode focusing on the current speaker, and some mobile-friendly portrait mode layouts.
However, we do want to provide our customers with the tools to build their own layouts, along with flexible controls during the call to deliver a richer content experience to their users. This includes custom branding and backdrops, arbitrary text overlays, and of course, flying emojis!
We are hard at work building all this, so watch this space for a follow up post!
Never miss a story
Get the latest direct to your inbox.