Daily’s developer platform powers audio and video experiences for millions of people all over the world. Our customers are developers who use our APIs and client SDKs to build audio and video features into applications and websites.
Today, as part of AI Week, Pauli Olavi Ojala discusses automation of video editing. Pauli is a senior engineer and architect of Daily's compositing framework VCS (Video Component System).
Our kickoff post for AI Week goes into more detail about what topics we’re diving into and how we think about the potential of combining WebRTC, video and audio, and AI. Feel free to click over and read that intro before (or after) reading this post.
These days people love watching bite-sized video clips, typically 15-60 seconds long, on platforms like TikTok, Instagram, and YouTube. For many user groups, this kind of short-form video has displaced more traditional social media content formats such as Twitter-style short text posts, Instagram-style static photos, and the classic extended YouTube video.
Businesses and content creators could reach their audiences in this popular new format, but they face a massive problem in how to produce the content. Creating simple tweets and picture posts is well understood and often automated by various tools. While YouTube-style long-form video can be laborious and also requires frequent posting, newer formats up the ante.
Short-form video manages to combine the most difficult aspects of both. Like with tweets, you need a high volume of content because the clips are so short and viewers are flooded. On the other hand, producing a great 45-second video can be as much work as making a great ten-minute video. Often it’s even harder — in the classic rambling YouTube format, a creator can often keep people watching simply by talking well, but a short reel must have tight editing, cool graphics, flashy transitions, and so on.
Although short-form video seems like a pure social media phenomenon today, it’s worth noting that social modes of expression and habits of content consumption tend to get integrated into other digital products over time. Consider Slack: a very popular business product, but the user experience has much more in common with Discord and Twitter than old-school business software like Outlook. Fifteen years ago it would have been unimaginable to use emojis and meme pictures in a business context. As a generation of users grows up with short-form video, its expressive features may similarly be adopted by great products in all kinds of verticals. Even plain old business meetings could benefit from tightly edited video summaries, especially if the editor could incorporate useful context from outside the meeting recording.
Meanwhile, we see at Daily that our customers often have a problem of abundance. They have the raw materials for interesting video content, but at massive volume. They can record down to the level of individual camera streams in their Daily-based applications, but nobody has the time or attention span to watch all those raw recordings. In the mining business they would call this a “low-grade ore" — there’s gold somewhere in this mountain of video, but extracting it isn’t trivial!
Could supply meet demand, and the mass of raw video be refined into striking short-form content? Clearly this problem can’t be solved by throwing more human effort at it. A modern gold mine can’t operate with the manual pans and sluice boxes from the days of the California gold rush. Likewise, the amount of video content that flows through real-time applications on Daily can’t realistically be edited by professionals sitting at Adobe Premiere workstations.
Mine, machine minds
Enter AI. Could we send a video editor robot down the audiovisual mine shaft to extract the short-form gold?
As we’ve seen over the past few years, large AI models have reached truly impressive capabilities in language processing as well as image recognition and generation. Creating high-quality textual summaries and relevant illustrations is practically a solved problem, which is why AI already has so many applications for traditional social media content.
But short-form video is a bit different because it tends to use multiple media formats in a dense time-based arrangement. The vocabulary available to a video editor is quite rich: there are cuts, text overlays, infographics, transitions, sound effects, and so on. Ideally these all work in unison to create a cohesive, compelling experience less than a minute long.
A large language model (LLM) like ChatGPT operates on language tokens (fragments of words). An image diffusion model like Dall-E or Midjourney operates on pixels. An audio model like Whisper operates on voice samples. We have some bridges that map between these distinct worlds so that images turn into words and vice versa, but a true multimedia model that could natively understand time-based audiovisual streams and also the underlying creative vocabulary needed to produce editing structures remains out of reach for now.
Waiting another decade for more generalized AI might be an option if you’re very patient. But if you’re looking to get a product advantage now, we have to come up with something else.
CutBot
The solution we’ve been working on at Daily is to break down the problem of video editing into a conversation of models with distinct and opposing capabilities.
We’re developing an experimental system called CutBot. It’s similar in design to a traditional kind of expert system, but it commands the vocabulary of video editing. (“Expert system” is an older form of AI modeling where a workflow is manually codified into a program. In many ways it’s the opposite approach to most present-day AI that uses tons of training data to create very large and opaque models.)
CutBot knows enough about the context of the video that it can apply a sequence of generally mechanical steps to produce a short-form reel whose superficial features tick the right boxes—rapid cuts, graphics overlays with appropriate progressive variation over time, and so on. What this system lacks is any kind of creative agency.
For that, CutBot has access to a high-powered LLM which can make creative decisions when provided enough knowledge about the source footage in a text format. We can use voice recognition and image recognition to create those textual representations. CutBot can also share further context derived from application-specific data. (In the next section we’ll see a practical example of what this can be.)
In this partnership of systems, the LLM is like the director of the reel, bringing its experience and commercial taste so it can answer opinion-based questions in the vein of: “What’s relevant here?” and “What’s fun about this?”
On the other side of the table, CutBot plays the complementary role of an editing technician who knows just enough so it can pose the right questions to the director, then turn those opinions into specific data that will produce the output videos. Note the plural—since we’re doing fully automated editing, it becomes easy to render many variations based on the same core of creative decisions, for example different form factors such as portrait or landscape video, short and extended cuts like 30 or 60 seconds, branded and non-branded versions, and so on.
A bit further down we’re going to show some early open source tooling we have developed for this purpose. But first, let’s take a look at a real example from a Daily customer.
Highlights from Cloud Poker Night
Cloud Poker Night is a fun and striking new way to play poker. The platform is aimed at a business audience, and it uses Daily to provide a rich social experience. You can see and hear all the other players just like at a real poker table, and a professional dealer keeps the game flowing.
Short highlight reels would be a great way for players to share the experiences they had on Cloud Poker Night. If these could be generated automatically, they could even be made player-specific, so that you can share your own best moments with friends on social media. What makes this quite difficult is that the game is so rich and carries so many simultaneous data streams — it wouldn’t be an easy task even for a human video editor.
In the image below, on the left-hand side is the Cloud Poker Night game interface as it appears to a player. On the right-hand side, we have a glimpse into the underlying raw data that is used to build up the game’s visuals:
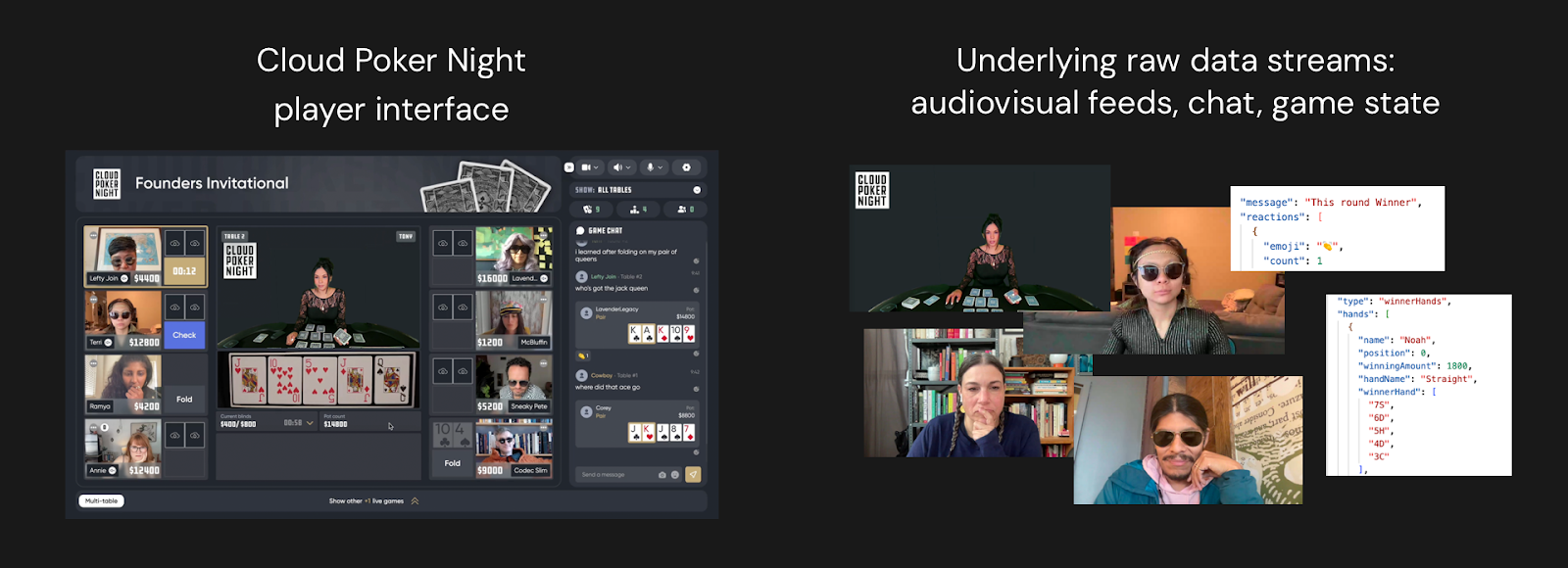
This is a great example of an application that has very interesting raw materials for short-form video, but the effort of producing reels manually is too great to even consider. A game session can last for an hour. There can be a dozen or more players across two tables. That would be a lot of video tracks for a human to watch.
In addition to these raw AV streams, there are also the game events like winning hands, emoji reactions sent by players, etc. A human editor would probably just watch the video tracks and try to figure out what was interesting in the game, but a computer can use the game event data and players’ emoji reactions to hone its attention onto interesting stuff more directly.
So we take these inputs and use a first stage of AI processing to create textual representations. Then the “partnership of systems” described in the previous section — CutBot and LLM — makes a series of editing decisions to produce a cut for the highlight reel:

Once we have the cut, it’s not yet set in stone — or rather, fixed in pixels. The output from the AI is an intermediate representation that remains “responsive” in the sense that we can render into multiple configurations. For example, having both portrait and landscape versions of the same reel can be useful for better reach across social media platforms:

We’ll discuss the specifics that enable this kind of responsive visual design in a minute. Before we jump to the rendering side, let’s pull together the threads of AI processing. What we’ve shown here with reel generation from Cloud Poker Night’s raw data is a prototype. How could this be deployed for a real-world application, and how would users access this functionality?
User interface considerations
CutBot isn’t a fully generalized AI. It’s a combination of the “dumb but technically qualified” editing-specific expert system and the “smart but loose” generic LLM. To some extent, the heuristics used by the expert system need to be tuned for each application. We’re still in the early stages of making this process more accessible to developers.
For the Cloud Poker Night example shown above, the tuning was done manually. The demo was programmed with some details of the poker application and the desired visual vocabulary for the video. Partially this was done using what could be called “low-code” methods. For example, the visual templates for the overlay graphics in the Cloud Poker Night clip were designed in the VCS Simulator using its GUI. It has a feature that outputs code blocks ready for use in Daily’s compositing system. Those code blocks can simply be copied over into the CutBot’s repertoire of graphics.
For some applications, the video generation process can be fully automated. This is a valid approach when you want to deliver the short-form videos as soon as possible, as would be the case for Cloud Poker Night. You’d usually want to enable players to share their highlight reels immediately after the game, and it doesn’t matter if the reels are 100% polished.
The other possible approach is to have a human in the loop providing input to the process. This means building a user interface that presents options from CutBot and lets the user make choices. For most users, this wouldn’t need to resemble the traditional video editing interface—the kind where you’re manually slipping tracks and trimming clips with sub-second precision. The paradigm here can be inverted because the cut is primarily created in conversation with the LLM-as-director. The end-user UI can reflect that reality and operate on higher-level content blocks and associated guidance.
VCSRender
What happens when CutBot has produced a cut — how does it turn into the actual AV artifacts, one or more output videos?
We mentioned before that producing multiple form factors and durations from the same AI-designed cut is a common requirement. For this reason, it’s not desirable to have the output from CutBot be precisely nailed down so that every visual layer is expressed in absolute display coordinates and animation keyframe timings. Instead, we’d like to have an intermediate format which represents the high-level rendering intent, but leaves the details of producing each frame to a smart compositor that gets executed for each output format.
As it happens, we already have such a thing at Daily — and it’s open source to boot. Our smart compositor engine is called VCS, the Video Component System.
VCS is based on React, so you can express dynamic and stateful rendering logic with the same tools that are familiar to front-end developers everywhere. This makes it a great fit for the compositor we need to generate videos from CutBot.
Until now we’ve provided two renderers for VCS:
- A server-side engine for live streaming and recording. It runs on Daily’s cloud and operates on live video inputs. You can access it via Daily’s API.
- A client-side engine that runs directly in the web browser. It operates on video inputs from a Daily room, or
MediaStreaminstances provided by your application. This library is open source. (You can create your own JS bundles directly, and we’re also working on a renderer package that will make it much easier to use the VCS engine in your Daily-using app.)
We’ll be adding a third renderer called VCSRender that’s specifically designed for batch rendering situations like these short-form videos.
VCSRender is an open-source CLI tool and library that produces videos from inputs like video clips, graphics, and VCS events that drive the composition. It’s a lightweight program with few dependencies, and it’s designed to adhere to the “Unix way” where possible. This means all non-essential tasks like encoding and decoding media files are left to existing programs like FFmpeg which already perform these admirably. This fine-grained division of labor makes it easier to deploy VCSRender in modern “serverless” style cloud architectures where swarms of small workers can be rapidly summoned when scale is needed, but no resources are consumed when usage is low.
VCSCut
VCSRender discussed above is fundamentally a low-level tool. To provide a more manageable interface to this system, we’re also releasing a program called VCSCut. It defines the “cut” file format which is produced by our CutBot AI. These cut files are expressed in a simple JSON format so it’s easily possible to create them with other tooling or even by manual editing.
VCSCut is really a script that orchestrates the following open source components:
- FFmpeg for decoding and encoding
- VCS batch runner for executing and capturing the VCS React state
- VCSRender for final compositing
Together these provide a rendering environment that’s well suited for short-form video. In a cloud environment, you could even split these tasks onto separate cloud functions orchestrated by the VCSCut script, with something like AWS S3 providing intermediate storage. This kind of design can be cost-effective for variable workloads because you don’t need to keep a pool of workers running so there’s no expense when the system isn’t used, but it still can scale up very rapidly.
It’s worth emphasizing that the VCSCut+VCSRender combo is in early alpha. It’s tuned for short-form video and is not a solution for every video rendering need. For long videos and real-time streaming sessions, we internally use GStreamer, an extremely mature solution with a different set of trade-offs. (There’s an interesting story to tell about how VCS works with GStreamer, but that will have to wait for another day!)
The alpha release will be part of the daily-vcs repo on Github. You can watch and star the repo if you want to stay up to date on the code directly! We’ll be talking about it on our blog and social media channels too. (And you can refer to our reference documentation for more information about VCS and Daily’s recording features.)
We are always excited to discuss these topics — you can find us on social media; join us on Discord; or find us online or IRL at one of the events we host.
Never miss a story
Get the latest direct to your inbox.