


NVIDIA Nemotron 3 Super, the new open source LLM launched by NVIDIA today, marks an inflection point for voice AI developers.
We've tested Nemotron 3 Super in voice agents, run our benchmarks against the model, and calculated the cost of running it in production. We can fine-tune this model. We can extensively post-train it using Nemotron's open data sets and open training code. Together with Nemotron 3 Nano (a 30B parameter model released in November), and Nemotron Speech ASR (a realtime speech-to-text model released in January), this model forms a stack that is the first meaningful open source alternative (and complement) to proprietary API services for voice AI developers.
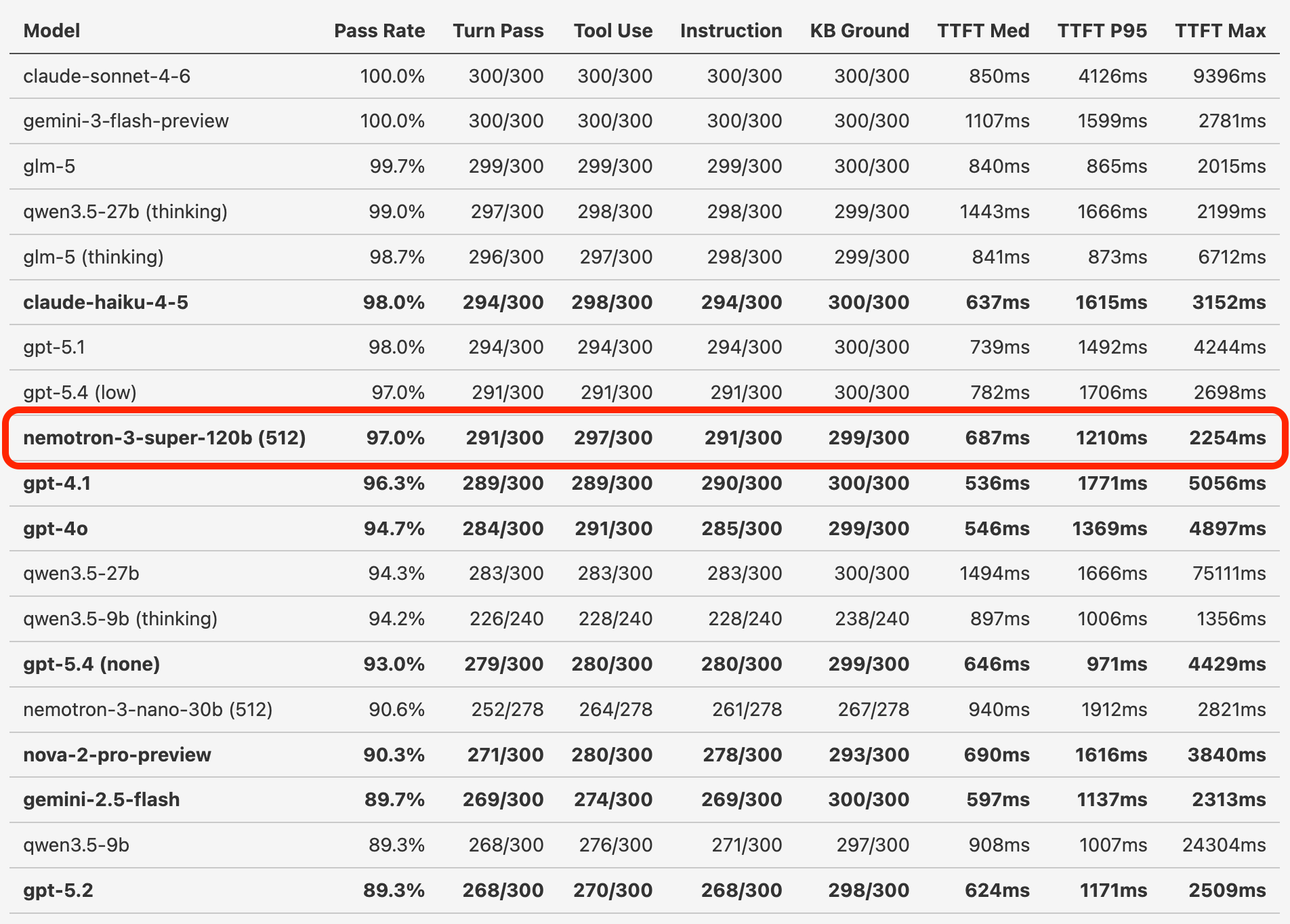
On our long-conversation voice agent benchmarks, Nemotron 3 Super performs at the same level as the new GPT-5.4 models. It also performs better than both GPT-4.1 and Gemini 2.5 Flash, which are the two most widely used models for production voice agents.
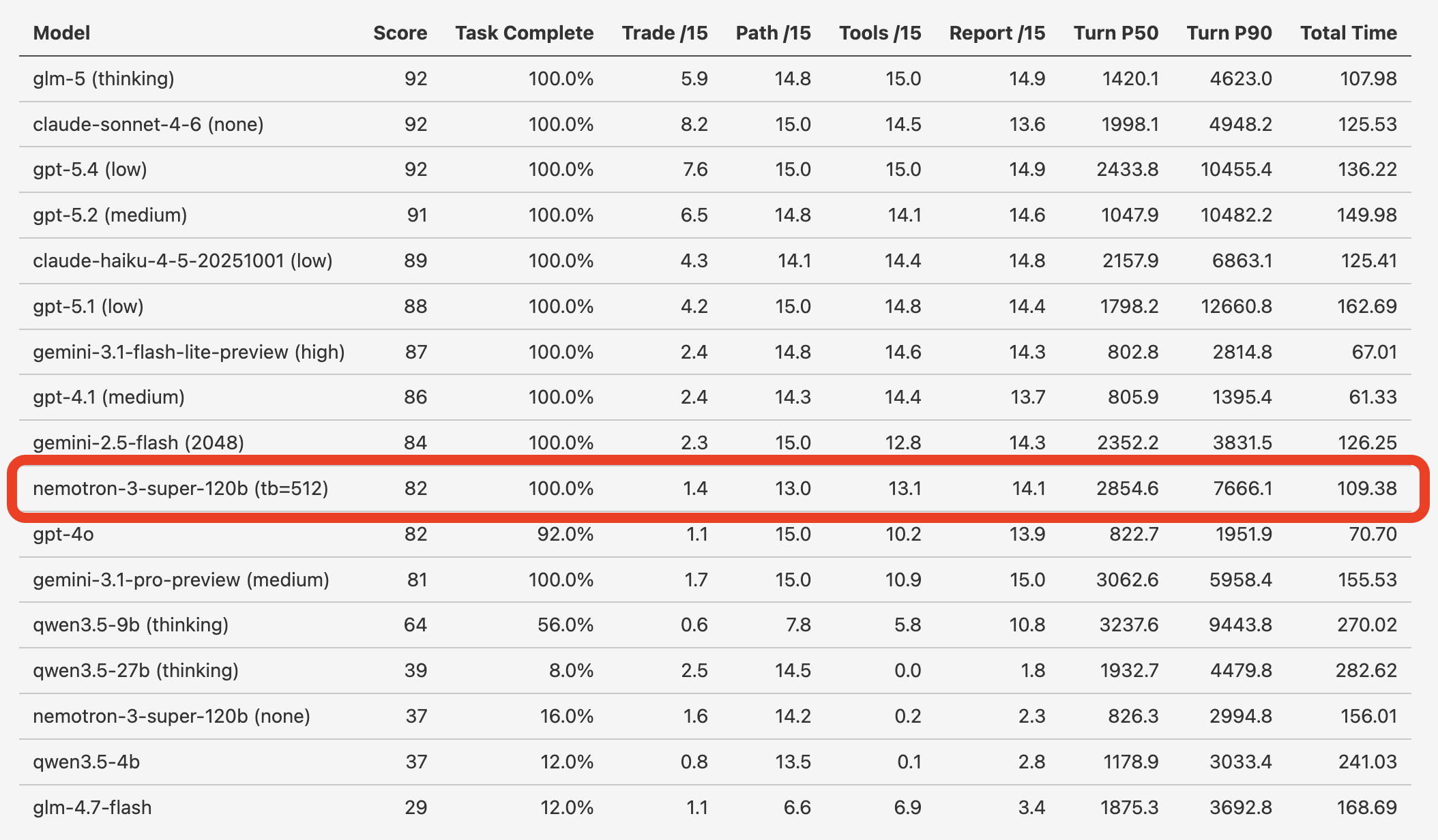
Today, we’re also introducing a new set of agentic task benchmarks: the Gradient Bang evals. Nemotron 3 Super is one of two open models in the top 10. The other is GLM-5, which is a 745B parameter model. (Roughly 6x the size of Nemotron 3 Super!)
The realtime AI systems we're building today are increasingly multi-model and multi-agent. We're building voice agents that orchestrate long-running sub-agents to search and compile information, agentic controllers for robots that fuse data from onboard sensors and implement hybrid local/cloud inference, and software interfaces that combine voice input and multi-modal output.
Voice agent performance requirements
These voice agent and realtime AI use cases are extremely challenging for LLMs.
- Voice conversations are multi-turn and open-ended.
- Responses must be fast. We need TTFTs under 700ms to build voice agents responsive enough for people to happily talk to.
- Many voice agents have fairly large system instructions. 4,000 tokens or more is not uncommon.
- Typical agents define several tools, and accurate tool calling is critical.
- Enterprise voice agents have demanding requirements for instruction following accuracy. For example, if the first step in a conversation with a healthcare patient is to confirm their identity, that step must be performed accurately, and the conversation must not proceed beyond that step until it’s done.
We maintain open source benchmarks that test instruction following accuracy, tool calling reliability, hallucinations/grounding, and latency. Our standard benchmark is the aiewf medium context eval. This benchmark is a 30-turn conversation with an 8,000 token system instruction and six tool calls.
As voice agent developers, we’re often in the position of having to choose between low latency and high intelligence. GPT-4.1 is the most widely used LLM for production voice agents. (As the core maintainers of the Pipecat open source framework, and the team behind the commercial voice hosting platform Pipecat Cloud, we have fairly comprehensive usage statistics.) And the benchmark shows why. GPT-4.1 is the fastest model that scores above 95%.
Nemotron 3 Super scores slightly above GPT-4.1 – 97% compared to 96.3%.
Inference tooling notes
One caveat for the benchmark numbers above: it’s not possible quite yet to do an apples-to-apples latency comparison between Nemotron 3 Super and other models.
The Nemotron 3 architecture is new and, from the perspective of those of us who've been writing transformer-centric inference code for the past couple of years, a little weird. (In a good way!) Nemotron 3 models have both transformer and Mamba layers. The Mamba layers compress context into a rolling, fixed-size state rather than a traditional transformer's key-value cache. This keeps the Mamba context small and keeps inference fast no matter how long the context is. But now we have two different state mechanisms that our inference tooling needs to manage and optimize.
So inference speed for Nemotron 3 models is not yet as fast as it is for older architectures. In particular, prefill caching for the Nemotron 3 hybrid Mamba-Transformer mixture of experts architecture is only partially implemented in the widely used inference frameworks like vLLM, SGLang, and TRT-LLM. But we expect this to change quickly as the open source community embraces these models.
For benchmarking BF16 and FP8 checkpoints of the model on NVIDIA B200 hardware on Modal, we used this command.
export TOKENIZERS_PARALLELISM=false
export VLLM_FLASHINFER_MOE_BACKEND=throughput
export VLLM_USE_FLASHINFER_MOE_FP8=1
export VLLM_FLASHINFER_ALLREDUCE_BACKEND=trtllm
vllm serve $MODEL_REFERENCE \
--host 0.0.0.0 \
--port 8000 \
--served-model-name nemotron-3-super-120b \
--async-scheduling \
--tensor-parallel-size 1 \
--swap-space 0 \
--trust-remote-code \
--reasoning-parser-plugin /opt/nim/nemotron_middleware/src/vllm_reasoning_parser_v2.py \
--reasoning-parser super_v3_enhanced \
--enable-auto-tool-choice \
--tool-parser-plugin /opt/nim/nemotron_middleware/src/vllm_tool_parser.py \
--tool-call-parser super_v3 \
--gpu-memory-utilization 0.9 \
--enable-expert-parallel \
--max-num-seqs 4 \
--no-enable-prefix-cachingThe base TTFT we’re seeing for this model on an NVIDIA B200 is ~38ms. Prefill processing can be as fast as 8k tokens per second. Generation throughput is roughly 200 tokens per second.
The NVFP4 quantization of Nemotron 3 Super runs on the NVIDIA DGX Spark desktop AI supercomputer, too.

We're 1,000 tokens per second prefill and 14 tokens per second generation on the DGX Spark, with this configuration.
docker run -d \
--name $CONTAINER_REFERENCE \
--gpus all \
--ipc=host \
--ulimit memlock=-1 \
--shm-size=32g \
-p 8001:8000 \
-v /home/ubuntu/models:/model \
-v /home/ubuntu/.cache/
-v /home/ubuntu/.cache/vllm_ubuntu:/home/ubuntu/.cache/vllm \
-v /home/ubuntu/.cache/flashinfer:/home/ubuntu/.cache/flashinfer \
-e HF_HOME=/home/ubuntu/.cache/huggingface \
-e HF_MODULES_CACHE=/home/ubuntu/.cache/huggingface/modules \
-e TRANSFORMERS_CACHE=/home/ubuntu/.cache/huggingface/transformers \
-e TOKENIZERS_PARALLELISM=false \
-e VLLM_FLASHINFER_MOE_BACKEND=throughput \
-e VLLM_FLASHINFER_ALLREDUCE_BACKEND=trtllm \
-e MAX_JOBS=1 \
--attention-backend TRITON_ATTN \
--enforce-eager'I <think>, therefore I am
Nemotron 3 Super is a reasoning model. It is trained to “think” before producing final output. The initial thinking segments are visible in the inference output and are wrapped in <think></think> tags.
You can disable reasoning. But, like almost all recent SOTA models, tool calling performance for Nemotron 3 Super is very poor with reasoning disabled. So we need to run the model in reasoning mode. But the initial thinking segment adds to response latency.
We can set a “thinking budget,” which forces the model to stop thinking after emitting a certain number of initial reasoning tokens. We did a parameter sweep to find the optimal thinking budget for the aiewf medium context benchmark. It turns out that setting a budget of 512 tokens is a good compromise between intelligence and latency. Because thinking is dynamic, most of the time we won’t hit the 512-token limit. But when we need those extra reasoning tokens, thinking for a few hundred milliseconds more to get an accurate tool call is worthwhile.
Here’s the distribution of thinking segment lengths, from a set of ~300 inference calls performed during an aiewf medium context benchmark test.
| Percentile | Tokens |
|---|---|
| Min | 11 |
| P25 | 78 |
| P50 | 203 |
| P75 | 265 |
| P90 | 288 |
We can fine-tune this model. (And we probably should!)
Voice AI developers have been in a funny position over the past year, as models have gotten better, but also slower.
Almost all recent SOTA models are post-trained as reasoning models. This has led to impressive improvements in agentic task abilities. But the focus on RL for reasoning has meant that new models often don’t perform well with reasoning disabled. Or they have minimum reasoning settings that all but guarantee latencies that are untenable for voice agent use cases.
OpenAI describes GPT-4.1 as the company’s “smartest non-reasoning model.” GPT-4.1 is almost a year old, which makes it a very old model in today’s incredibly fast-moving AI landscape. OpenAI may never release another generation of non-reasoning models!

From https://developers.openai.com/api/docs/models
So where does that leave those of us building for production use cases – like voice agents – that require low latency?
Nemotron 3 Super provides a path forward. Not the model in the form that was released today (though it’s an excellent model). But in future versions that might be created by the NVIDIA model team, or might be created by the open source community.
The Nemotron 3 models are completely open source. The weights are open, of course. And, in addition, the training data sets, training code, and inference tooling are open source.
This opens up many possibilities for fine-tuning. Or even for doing more intensive post-training than would normally be described as fine tuning.
The “reasoning heavy” RL that is the current norm for SOTA models is only one point on a multidimensional tradeoff surface. I’d like to see a version of Nemotron 3 Super that is additionally post-trained specifically to improve tool calling with reasoning turned off. My experience working on models suggests this is a data set generation and engineering task, not a research question. We can very likely hill climb on function call accuracy metrics in a fairly straightforward way.
Let me know if you’d like to work on this project. Training models is fun!
Deploying this model
You can run Nemotron 3 Super on a range of NVIDIA data center GPU configurations. My preferred stack for testing the model has been NVIDIA DGX B200 instances on the Modal AI cloud. Modal’s tooling makes it easy to deploy different inference server configurations, spin up capacity to run benchmarks and demos, and then spin down those applications so I’m only paying for the time I’m actually using the GPUs.
Here’s some sample code for running Nemotron on Modal.
Modal also supports a variety of low-latency networking capabilities and deployment components that are very, very useful for running voice agent inference at scale. And the Modal team also has lots of experience supporting voice agent use cases.
We did an NVIDIA livestream last month about using Nemotron models, Modal infrastructure, Pipecat, and Daily WebRTC for voice AI. Check that out if you’re interested in seeing a really great code walk-through from Ben, who builds this stuff at Modal.
And come hang out with us in the Pipecat Discord if you’re interested in general discussion about voice AI models, tooling, orchestration, and infrastructure.
Never miss a story
Get the latest direct to your inbox.