


NVIDIA released a new multilingual speech-to-text model today: Nemotron 3.5 ASR, ideal for voice agents.
This model is available in both multilingual (Nemotron 3.5 ASR) and English-only (Nemotron 3 ASR) checkpoints. It's the lowest-latency STT model we’ve tested. It’s also completely open source, fine-tunable, and you can host it on your own infrastructure.
Headline numbers from the Pipecat stt-benchmark:

The multilingual model is faster than any other model in the benchmark, with respectable accuracy. The English-only model is equally fast, with accuracy very close to the best-scoring models available today. This defines a new point on the Pareto frontier of latency/accuracy.
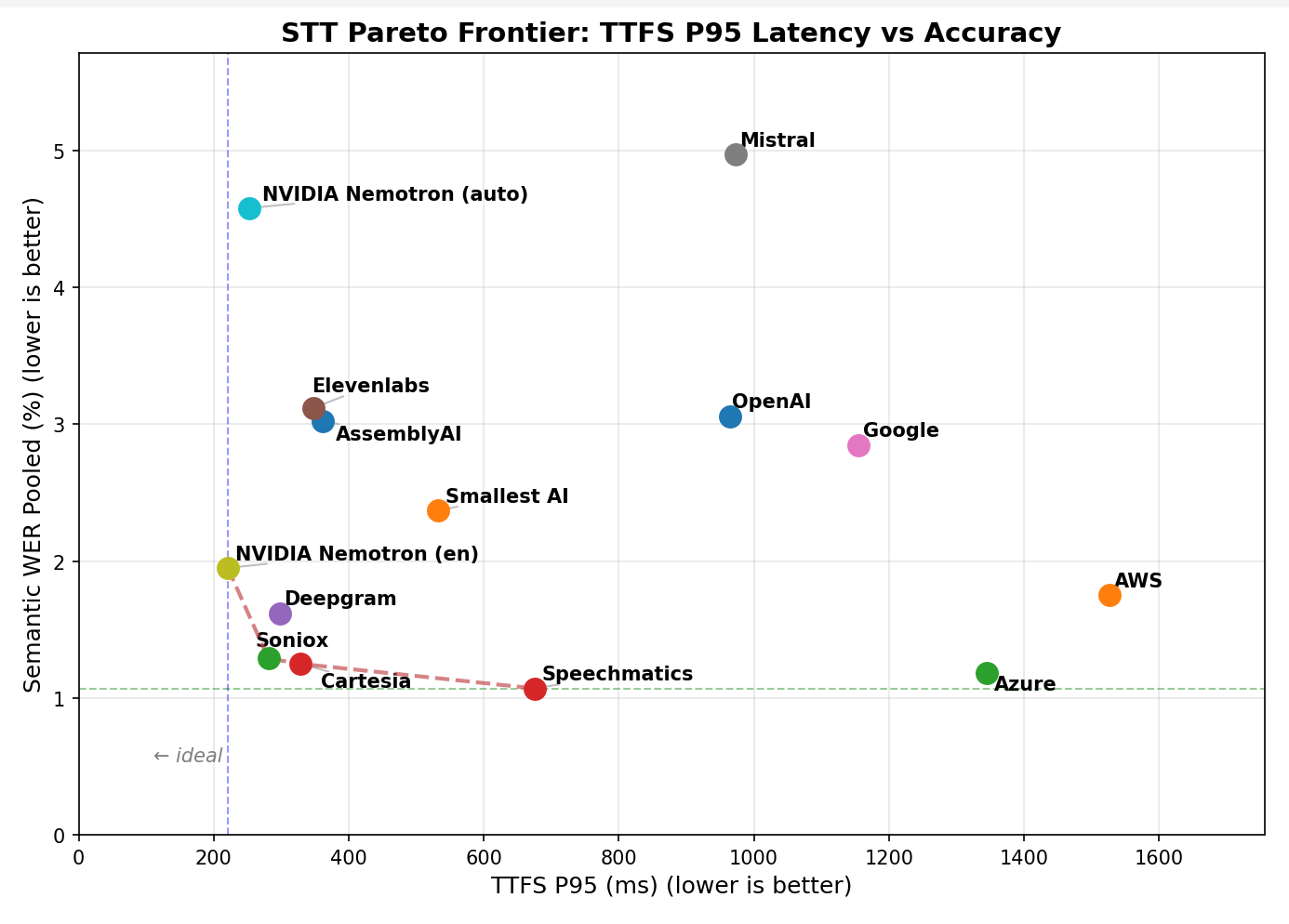
The benchmark above is open source. All code is here.
The latency is configurable, by setting the audio processing “chunk size.” Larger chunk sizes allow for slightly higher accuracy. For voice agents, we always configure transcription for the lowest possible latency. The chunk size is configurable dynamically, though, so if you have both voice agent and batch transcription use cases, you can serve both use cases with a single model deployment.
Being able to host the model yourself has a number of advantages.
- Many enterprises need to keep all voice agent data processing inside their own security and compliance boundary.
- You control capacity planning and can prioritize latency. (Including minimizing the spread between median latency and latency under heavy load).
- Significant cost savings are possible.
The per-agent cost per hour can be $0.01, or even lower. If you host yourself, you will need to account for things like base load usage commits, auto-scaling, redundancy, and multi-region deployments. So a back of the envelope per-hour cost estimate for an enterprise deployment is probably closer to $0.05/hour. For comparison, typical transcription API costs from major providers range from $0.10 - $1.00 per hour
Here’s the math for the per-hour cost. An optimized C++/CUDA server for Nemotron 3.5 ASR scales very well. We recommend running on NVIDIA L40S, because it’s much easier to purchase L40S capacity than, say H100 or other larger GPUs that are in great demand for serving LLMs! Here are concurrency and latency numbers for simultaneous transcription streams, for Nemotron 3.5 ASR on an NVIDIA L40S. We want to keep finalization time below ~50ms even when heavily loaded. (That’s how we keep the overall “time to final segment” number, measured from the client, below ~250ms). So the “safe” max concurrency is ~96 streams.
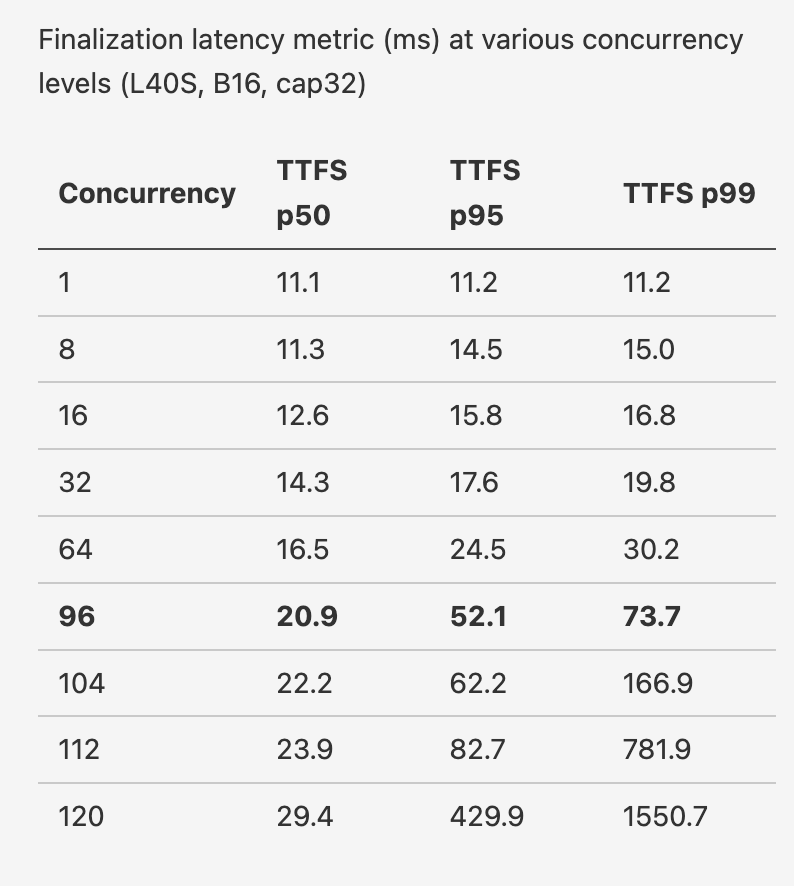
An L40S costs about $1.50 / hour. We can safely handle 200 voice agent WebSocket connections to this server, because voice agents are transcribing only when the user is talking. (In real-world use cases, less than half the time.) So the per-hour cost is less than $0.01 if you’re running this server at full capacity.
Of course, if you need to scale up and scale down, you’ll need to account for over-provisioning. On the other hand, if you have a consistent base load usage and are willing to sign annual contracts, you can pay less for your GPUs.
Because Nemotron 3.5 ASR is completely open source, you can modify it for your use case. The NVIDIA team that built this model also provides a full set of tools for fine-tuning the model. They have a great technical explainer post about fine-tuning Nemotron 3.5 ASR.
You can, for example, run a fine-tune to optimize the model for two specific languages. This takes the excellent general capabilities of the model, which are spread evenly across 40 languages, and concentrates them in the two languages that you are targeting.
These fine-tuning tools are always evolving. There’s a new coding agent skill that makes building your own, customized, transcription model more accessible than ever before!
We’ve created a repo with the C++ server used for the benchmark tests above, and a Python server that can automatically route between the multi-lingual and English versions of the model based on dynamic queues from Pipecat.
Never miss a story
Get the latest direct to your inbox.