

Last month, we introduced you to Storybot, a really fun demo of talking to an LLM. But when it comes to what’s possible with Daily’s AI toolkits, we’re just getting started.
Communicating across language barriers has been a problem since long before computers even existed. In The Hitchhiker’s Guide to The Galaxy, Douglas Adams solves the age-old problem with the Babel Fish, a creature that translates any speech it hears into your native language for you:
Fortunately, we can use Daily’s AI toolkits to solve this problem without having to jam anything into your ear! (Well, you can use earbuds if you want, but that’s up to you.) We’ve built a demo of live language translation using the architecture from the Storybot app. In this post, we’ll dig into the details of how it works.
If you’re looking at the scroll bar on this post and thinking you’d rather start with a high-level overview, we’ve made a video just for you:
Conceptually, the problem of live translation breaks down into four steps:
- Convert each phrase of spoken audio into text (speech-to-text).
- Translate the phrase into the desired language(s).
- Generate spoken audio of the translated phrase.
- Play back that audio for participants in the call that want to hear the translated language.
Additionally, some users may want subtitles in the original and/or translated language. More on that later.
In the Storybot post, we mentioned these three important ideas when building your own voice-driven LLM app:
- Run everything in the cloud (if you can afford to).
- Don’t use web sockets for audio or video transport (if you can avoid them).
- Squeeze every bit of latency you can out of your data flow (because users don’t like to wait).
The daily-python app
You can find the source code for the daily-python app in the server directory of the llm-translator repo.
We’ll build this with daily-python so we can run and test it locally to start, but eventually, you’ll want to deploy this to your web host of choice, or use a cloud AI platform like Cerebrium.
Step 1: Speech to text
The Daily platform handles speech-to-text for us. A simple call to start_transcription() enables Daily’s call transcription, powered by Deepgram. The transcription phrases are available as app messages, and daily-python lets us set up an event handler that gets called whenever we receive an app message. In fact, there’s even a convenience method that specifically looks for transcription messages:
# daily-llm.py
self.client.join(self.room_url, self.token, completion=self.call_joined)
# ...
def call_joined(self, join_data, client_error):
self.client.start_transcription()
# ...
def on_transcription_message(self, message):
# Ignore translators, whose names start with "tb-"
if not re.match(r"tb\-.*", message['user_name']):
print(f"💼 Got transcription: {message['text']}")
self.orchestrator.handle_user_speech(message)
else:
print(f"💼 Got transcription from translator {message['user_name']}, ignoring")
When our app receives a transcription message, it’s calling a function named handle_user_speech() in our Orchestrator instance. This is an object that, well, orchestrates the functionality of the app: It interacts with the Daily call client, as well as the various AI services we’re using in the call.
Step 2: Translation
The next step is converting the received transcript to the desired language. The orchestrator does that by creating a new thread and calling its own method, request_llm_response():
def handle_user_speech(self, message):
# TODO Need to support overlapping speech here!
print(f"👅 Handling user speech: {message}")
Thread(target=self.request_llm_response, args=(message,)).start()
def request_llm_response(self, message):
try:
msgs = [{"role": "system", "content": f"You will be provided with a sentence in English, and your task is to translate it into {self.language.capitalize()}."}, {"role": "user", "content": message['text']}]
message['response'] = self.ai_llm_service.run_llm(msgs)
self.handle_translation(message)
except Exception as e:
print(f"Exception in request_llm_response: {e}")
request_llm_response() builds an array of messages that serve as the context for GPT-4, the large language model (LLM) we’re using in this app. In this app, we only have two messages in our context: The system instruction that tells the LLM to respond by translating the next message, and the user message containing the phrase we want translated. We call the run_llm() function of our configured service, which actually makes the API call to GPT-4.
The LLM response is passed to the handle_translation() function, which we’ll look at next.
def handle_translation(self, message):
# Do this all as one piece, at least for now
llm_response = message['response']
out = ''
for chunk in llm_response:
if len(chunk["choices"]) == 0:
continue
if "content" in chunk["choices"][0]["delta"]:
if chunk["choices"][0]["delta"]["content"] != {}: #streaming a content chunk
next_chunk = chunk["choices"][0]["delta"]["content"]
out += next_chunk
#sentence = self.ai_tts_service.run_tts(out)
message['translation'] = out
message['translation_language'] = self.language
self.enqueue(TranslatorScene, message=message)The OpenAI Python SDK supports streamed responses, where instead of waiting to generate an entire sentence or paragraph, we get a single word at a time. If you’ve used ChatGPT in the browser, you’re probably familiar with the way the words appear quickly, one after another; the chunked API response works the same way. We want to generate the entire translated phrase as a single chunk of audio, though, so we wait until we’ve received all of the chunks before the next step.
Step 3: Text to speech
Generating audio is where we introduce one of the most important parts of the architecture: Scene playback.
daily-python allows us to do lots of things asynchronously—LLM completions, audio generation, image generation and more—but the scene architecture makes sure we don’t try to play back three different audio chunks at once. Let’s dig into how it works.
When the orchestrator has a new piece of content it wants to play back, it enqueues a new Scene. Each scene has two methods: prepare() and perform(). As soon as a new Scene instance is enqueued, it starts running its prepare() method asynchronously. This is where we do things like fetching audio from the text-to-speech API, or Storybot asking DALL-E to generate an image based on the prompt we’ve created.
The orchestrator can queue a bunch of scenes in quick succession, and they’ll all invoke prepare() immediately, so they’re hopefully ready to go by the time their perform() method is called.
Step 4: Audio playback
Speaking of which, as soon as the orchestrator starts scene playback, it will grab the first Scene in the queue and call its perform method. The perform method runs synchronously, one at a time in the order the scenes were queued. Each scene’s perform method waits for its prepare method to complete, if necessary, and then plays its video and audio.
In this demo, we’re taking advantage of the fact that Deepgram returns translations separately for each participant in the call. The translator app supports using Azure Speech or PlayHT for text-to-speech generation, and both services support many different simulated voices, so we’re using a different voice for each unique participant ID. Since one Python process handles each different translated language, the Scene architecture prevents the translated voices from speaking over each other, even if the original conversation had a bit of overlap.
Now, if you were to start three different translators for French, Spanish, and Japanese, and then join a call in Daily Prebuilt, you’d hear pure chaos—every time someone spoke, you’d hear it repeated in three languages! We’ll handle that problem with some flexibility from daily-react in the client app.
The client app
You can find the source code for the daily-python app in the client directory of the llm-translator repo.
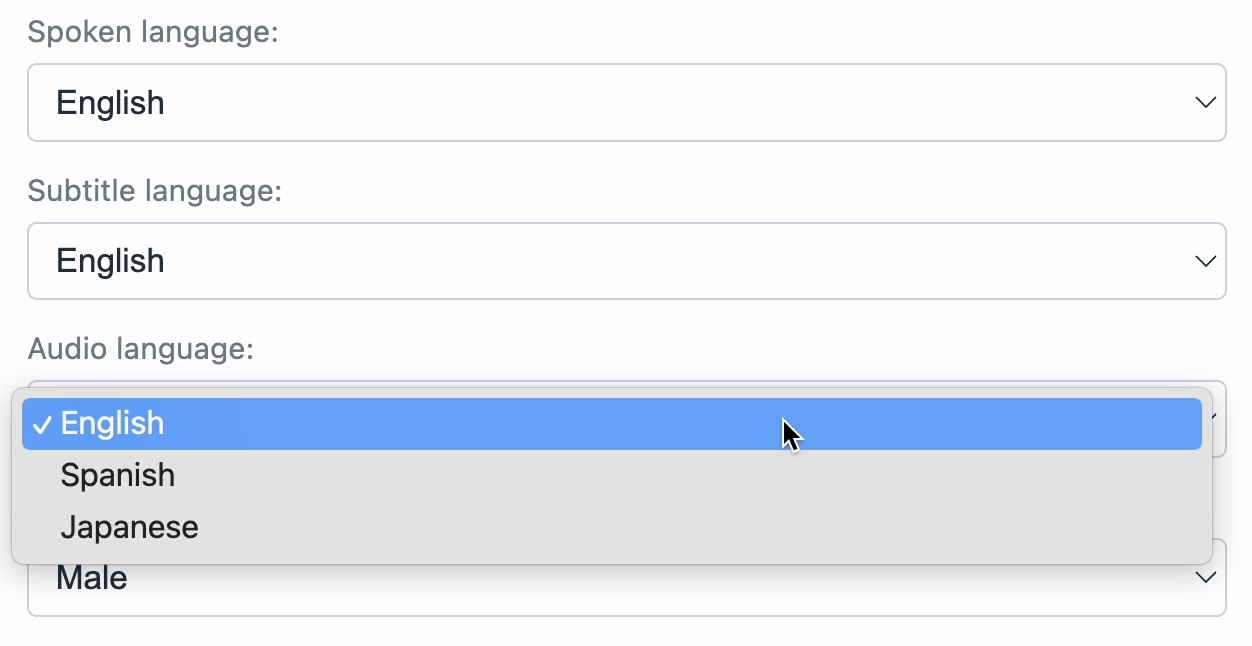
The client app is built from our daily-react example app, with a few important changes. First, we’ve added dropdowns to the “hair check” screen to select the language you’re speaking, as well as the language you’d like for transcripts and audio:
In App.js, we set up an event listener to send our language settings to everyone else on the call when we join the meeting, and request for everyone else to send us their language settings. This is similar to how we sync chat history in Daily Prebuilt:
// App.js
callObject.once('joined-meeting', () => {
// Announce my language settings for everyone on the call,
// since daily-python doesn't support session data yet
callObject.sendAppMessage({ msg: 'participant', data: { lang: lang.local } });
callObject.sendAppMessage({ msg: 'request-languages' });
});
This way, everyone knows what language I’m speaking, and I know what translators are available.
We added a Subtitle component to the Tile component. Subtitle watches for app messages containing translations in the desired language, and displays them on the speaker’s video tile:
// components/Subtitle/Subtitle.js
const sendAppMessage = useAppMessage({
onAppMessage: (ev) => {
if (lang.local?.subtitles === ev.data?.translation_language && ev.data?.session_id === id) {
setText(ev.data.translation);
if (textTimeout.current) {
clearTimeout(textTimeout.current);
}
textTimeout.current = setTimeout(() => {
setText('');
}, 7000);
}
},
});We handle the audio in a useEffect hook in the Call component. Since each participant (humans and translators) gets their own audio element on the page, we can loop through them and set their volume levels, based on the language information we got from the app messages when we joined the call. Here’s what we do for each one:
- If this is a person and they’re speaking the language I want to hear, set them to full volume. Otherwise, lower their volume so I can still hear when they’re talking, but I’ll be able to hear a translator over them.
- If this is a translator and it’s outputting a language I want to hear, set it to full volume. Otherwise, mute it.
Here’s the code:
audioTags.forEach((t) => {
if (t.dataset.sessionId) {
if (lang.remote[t.dataset.sessionId]) {
// this is an audio tag for a remote participant
const langData = lang.remote[t.dataset.sessionId];
// if their spoken language isn't what I want to hear, turn them down
if (langData.spoken !== lang.local.audio) {
t.volume = 0.1;
} else {
t.volume = 1;
}
} else if (lang.translators[t.dataset.sessionId]) {
// This is the audio tag for a translator
const langData = lang.translators[t.dataset.sessionId];
if (langData.out === lang.local.audio) {
t.volume = 1;
} else {
t.volume = 0;
}
}
}
});
There’s still work to do to integrate this into your application. For example, you may want to adjust the speed of the generated audio to keep it from drifting too far behind the original speech. When using the Azure backend, you can adjust playback speed with the “prosody” element, as shown in the run_tts() function in services/azure_ai_service.py:
ssml = f"<speak version='1.0' xml:lang='{lang}' xmlns='http://www.w3.org/2001/10/synthesis' " \
"xmlns:mstts='http://www.w3.org/2001/mstts'>" \
f"<voice name='{voice}'>" \
"<mstts:silence type='Sentenceboundary' value='20ms' />" \
"<mstts:express-as style='lyrical' styledegree='2' role='SeniorFemale'>" \
"<prosody rate='1.05'>" \
f"{sentence}" \
"</prosody></mstts:express-as></voice></speak> "
Conclusion
We think the implications of this use case are massive. Live translation can democratize communication in all sorts of contexts: patient care, virtual events, education, and more. We hope this ‘deep dive’ post helps you understand how you can start using daily-python to bring AI into real-time video and audio in all sorts of interesting ways.
What new, voice-driven applications are you excited about? Our favorite thing at Daily is that we get to see all sorts of amazing things that developers create with the tools we’ve built. If you’ve got an app that uses real-time speech in a new way, or ideas you’re excited about, or questions, please ping us on social media, join us on Discord, or find us online or IRL at one of the events we host.
Never miss a story
Get the latest direct to your inbox.