



An overview of strategies for recording WebRTC calls. On the client? In the cloud? Let’s look at all the options.
Some things in software development seem fairly straightforward at first glance, but then unfold into endless layers of complexity as soon as you start looking deeper. Recording a WebRTC video call is definitely that kind of software feature.
“How hard can it be,” you may think, “you just need to write the call into a video file… Somehow… Somewhere… Shouldn’t cost extra… Of course, it needs to be failure-proof even if someone’s computer goes away… With all the same features that the live participants experience… And maybe it even needs to be editable? Or at least a regular seekable MP4 file? Immediately available for download? Or could it be rendered only after the call finishes? Wait, this sounds like a lot actually.”
Fortunately, you don’t have to figure it out alone! This guide aims to help you to understand the possibilities and limitations of video call recording. We’ll look at the design factors you need to consider when deciding on a WebRTC recording solution, as well as the different implementation strategies that are available and which ones we at Daily consider best practices.
Choosing your point of view
Let’s start by considering a question that may be non-obvious. Even before you choose where your recording should be stored, and how that data might get there, you need to decide whose viewpoint you’re actually going to record. Meet Alice, Bob and Cynthia who are on the call…

Should your recording simply represent what some specific participant saw on their computer/device throughout the call? That would be a client-side direct recording. It’s essentially like a screen capture of the video call user interface.
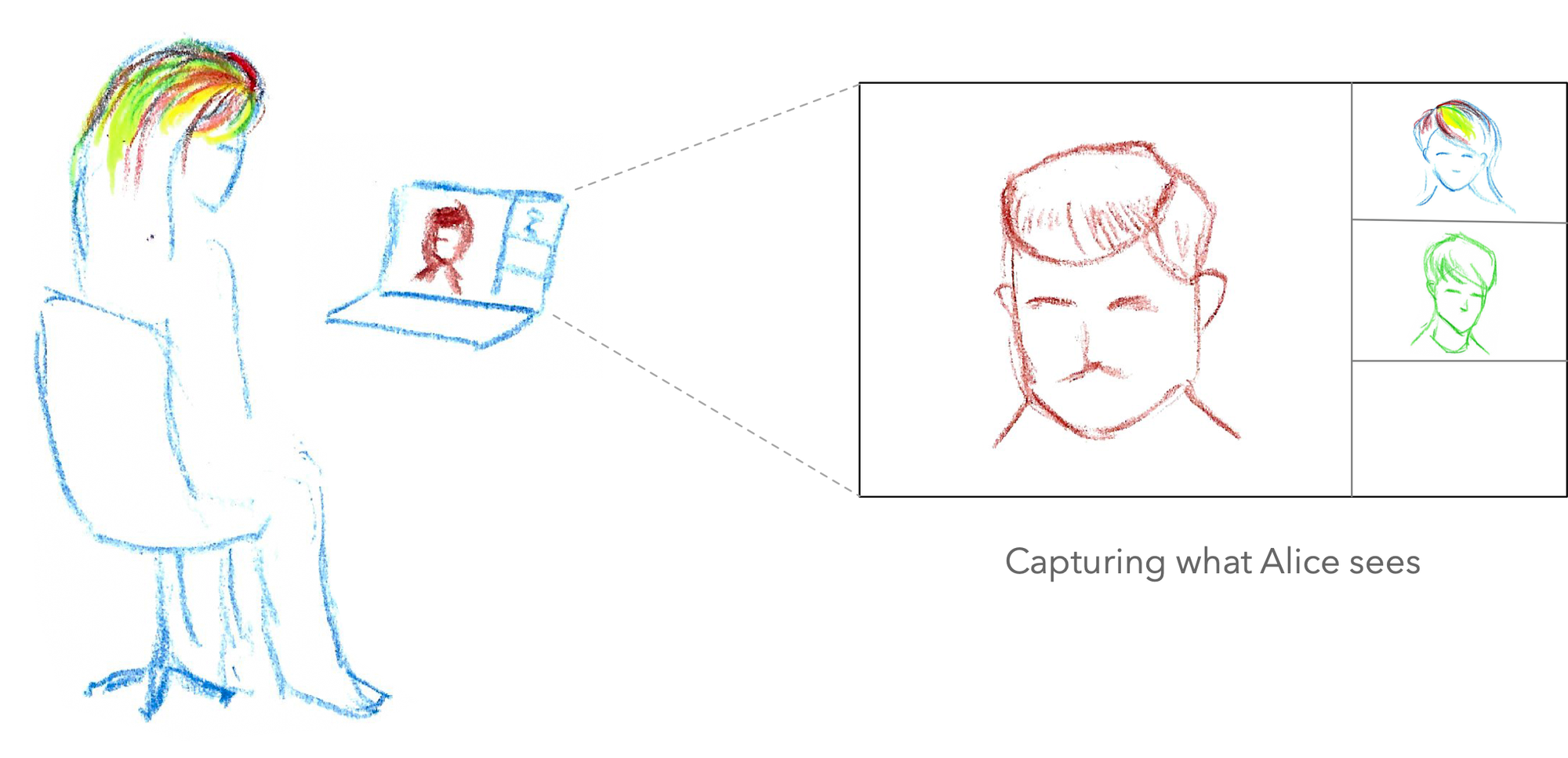
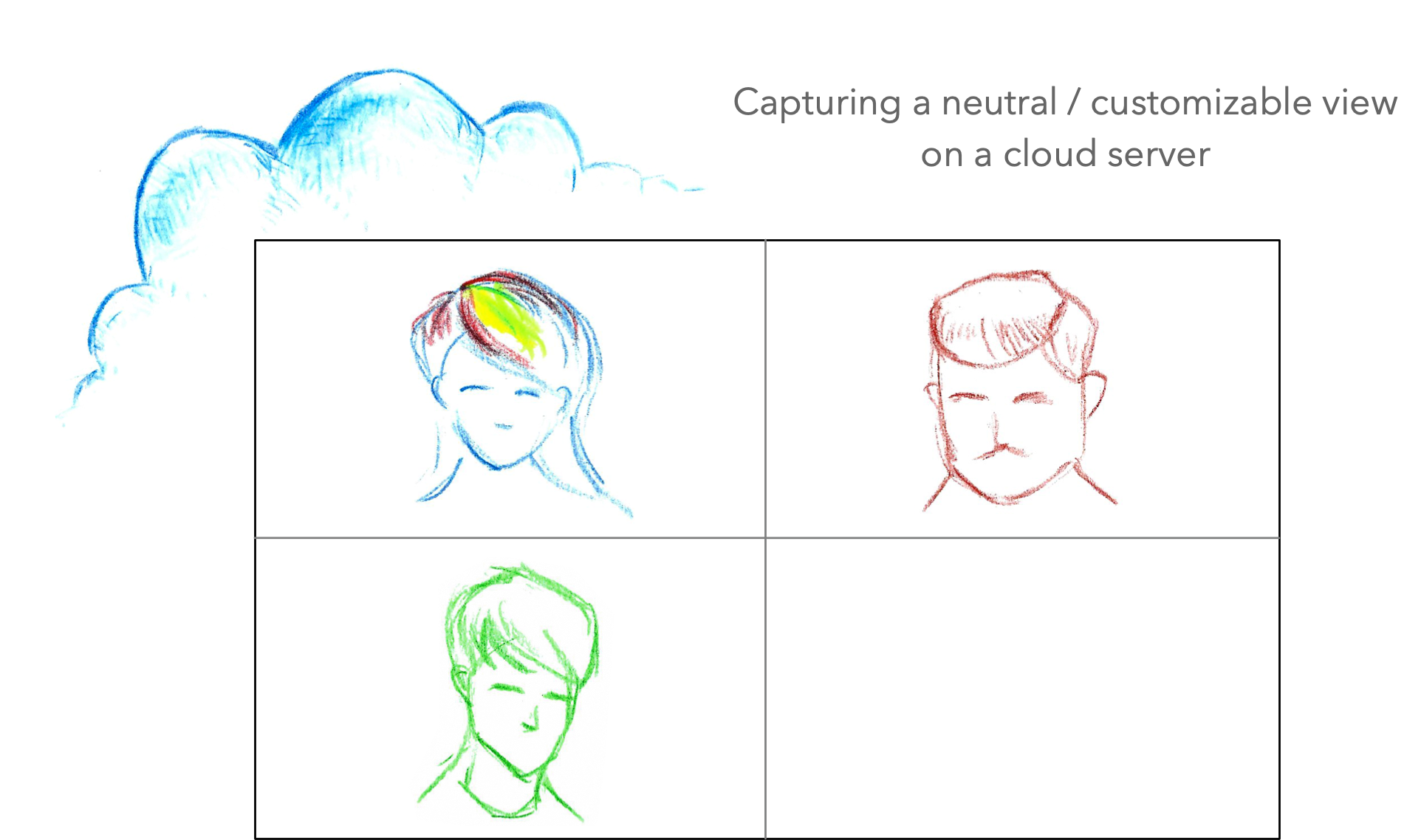
Or maybe you want to capture the video call from a neutral viewpoint that’s not exactly any of the participants? The advantage of this approach is that this kind of recording can be configured on the fly to offer an appearance designed purely for the viewers who were not present on the call. (For example, a participant usually has an always-on “self view” of their own camera, but it makes little sense to show that on a recording meant to be watched by others.) This kind of separate viewpoint rendering would typically be achieved by using server-rendered recording.
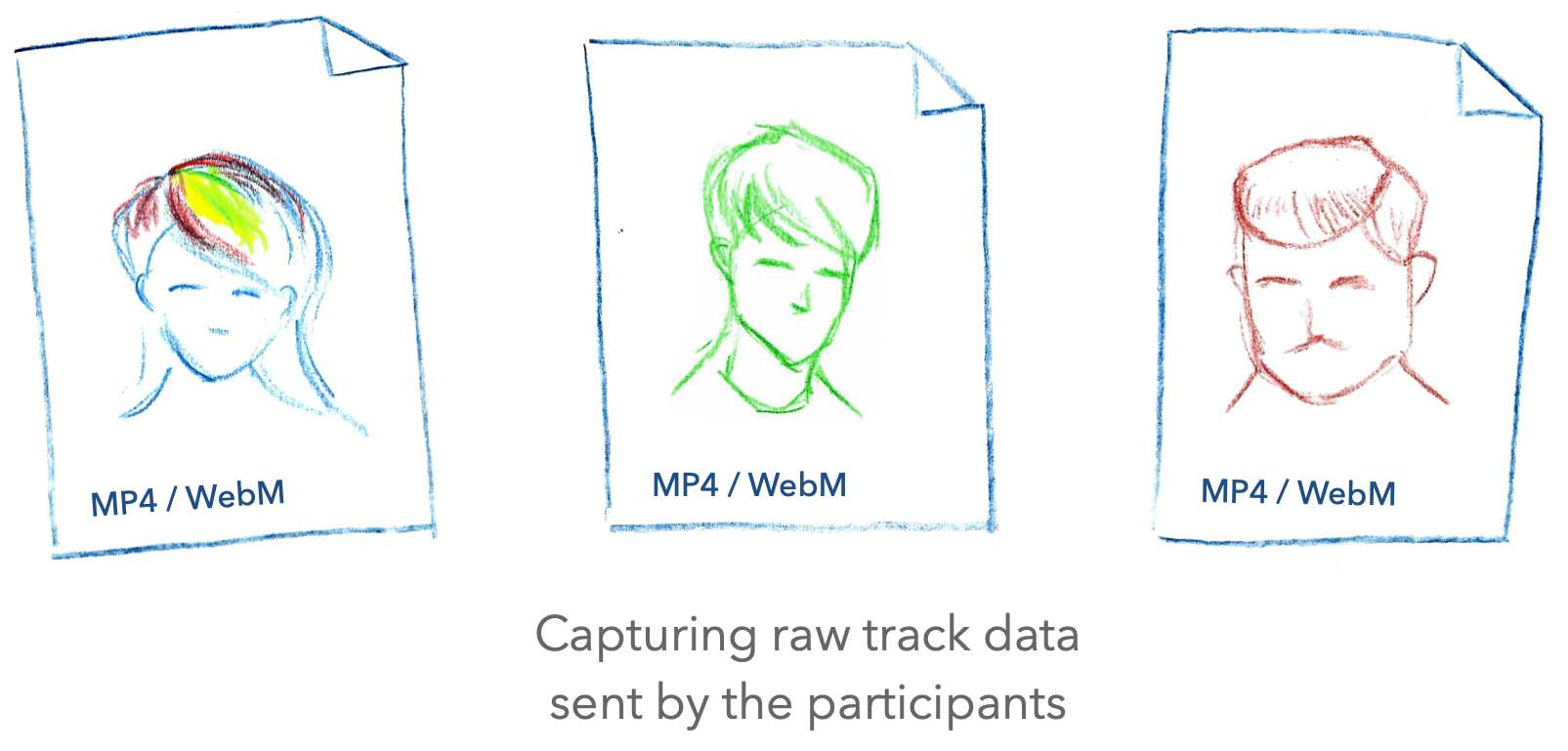
Or, you could side-step the question entirely and say this can be decided later. Instead of recording a specific viewpoint to a file, how about we record all the different participants’ video streams individually into separate files? Then we could create the final video as a post-production effort, either using some kind of automated tool or simply by importing those individual recordings into a video editing application for manual editing and production. This is often called raw track recording, or post-processed server recording (if the final edit is done on a server). You might try to do it on a client too.
What aspects should we evaluate when trying to decide between these approaches?
The trade-off space
Here I’ll explain five primary dimensions to consider. No solution will align perfectly on all these, so it often comes down to choosing your trade-offs. If your needs lie at the extreme end of any particular dimension—for example, you’re very cost-sensitive, or the recording must be available immediately in the cloud—that will limit your options elsewhere.
Flexibility
- What can you render? Can layouts be switched on the fly? What about captions, logos, and dynamic graphics overlays?
- Where can you send your recording? Is it possible to support multiple destinations like e.g. CDN distribution?
- What kind of events can you deal with? What happens when participants leave or join? Or if their video or audio is degraded or lost?
- When can you make these decisions? Are they automatic (and set in stone) during the call? Or can you fix issues in post-processing after the call has finished?
Scalability / robustness
- What happens when you have a large number of participants?
- Can we keep them all properly synchronized? (This could be a challenge, particularly with the raw tracks / post-processing approach.)
- What about multiple destinations? Are you planning to send the file to several video platforms, or do you perhaps need different versions for different audiences?
- Is the rendering and encoding load placed on a single bottleneck or point of failure? For example, client-side recording that depends on a participant's own computer will be more fragile than handling recording on a server.
Compatibility
- What can you do with the file(s) that are recorded? Can they be uploaded directly to another video service, or do they need further processing? (Mainstream video platforms like Facebook/Instagram have strict requirements for what type of video files you can upload via their API.)
- Do recorded video files play back with full seeking capabilities in a video player app? (This may sound like an oddly specific concern, but it’s actually fairly difficult to achieve because seek capability depends on how the video file was produced.)
Immediacy
- Do you need the video file to be immediately available? If so, raw tracks / post-processed recording won’t work. Storing individual participants’ videos is more flexible, but the trade-off is that the editing process needs to run after the call is finished. It means your final video won’t be available for at least a few minutes, or even hours for very long/complex videos.
- If you’re sending the video to multiple destinations, are those written in real time or uploaded later?
Cost
- Do you have a budget? It’s simply more expensive to use a server than to record on the client (which effectively just means “recording on the computer of one of your participants” — you’re offloading the work to them.) If your budget is literally zero, client-side is probably what you need to be looking at.
- Is time or money the primary concern? If server-side recording is what you need, then you practically need to maintain a complex media server yourself, or use a platform provider like Daily. We are committed to making Daily affordable regardless of whether your use case is big or small. You can read about our pricing, and Daily also has a startup program. But we’re going to give all the options their fair shake in this article! We’ll explain the various self-built options below so you can decide for yourself which is right for you.
- If you go with a platform solution, what are the tradeoffs? A provider like Daily may offer multiple recording options, so you can pick one that’s the best fit for your budget. We’ll look at this in some more detail in the implementation section next.
Implementation strategies
Armed with the above framework for evaluating recording methods, let’s look at some typical ways that a developer might actually build out a WebRTC recording feature. We’ll first consider client-side approaches as they tend to be more easily implemented, followed by the more involved server-side solutions:
- Ad hoc client recording
- Browser API client recording
- Browser API client raw tracks
- Browser API client recording directly to cloud
- Server-rendered recording using a headless browser
- Server-rendered recording using a media pipeline
- Server-rendered raw tracks
Note that some of these ideas are realistically too limited to be of practical use! To distinguish the good stuff from the chaff, we’ll award a gold star emoji—⭐️—to ideas worthy of being considered best practices, a thumbs-down—👎—to those that should be discarded right away, and a thinking face—🤔—for the difficult case when there are serious downsides, but it may still be the right choice for your application depending on your resources.
Ad hoc client recording 👎
This is probably the first thing that comes to mind for a developer when faced with the task of recording a video call. “Ad hoc” means “for this one purpose”, and that’s the essence of this solution—it doesn’t scale.
What if we just do a screen capture of someone’s browser? It could be done in a very low-tech way using a desktop operating system’s screen recording tool (e.g. QuickTime Player on macOS), or in a somewhat more high-tech way using an application like OBS.
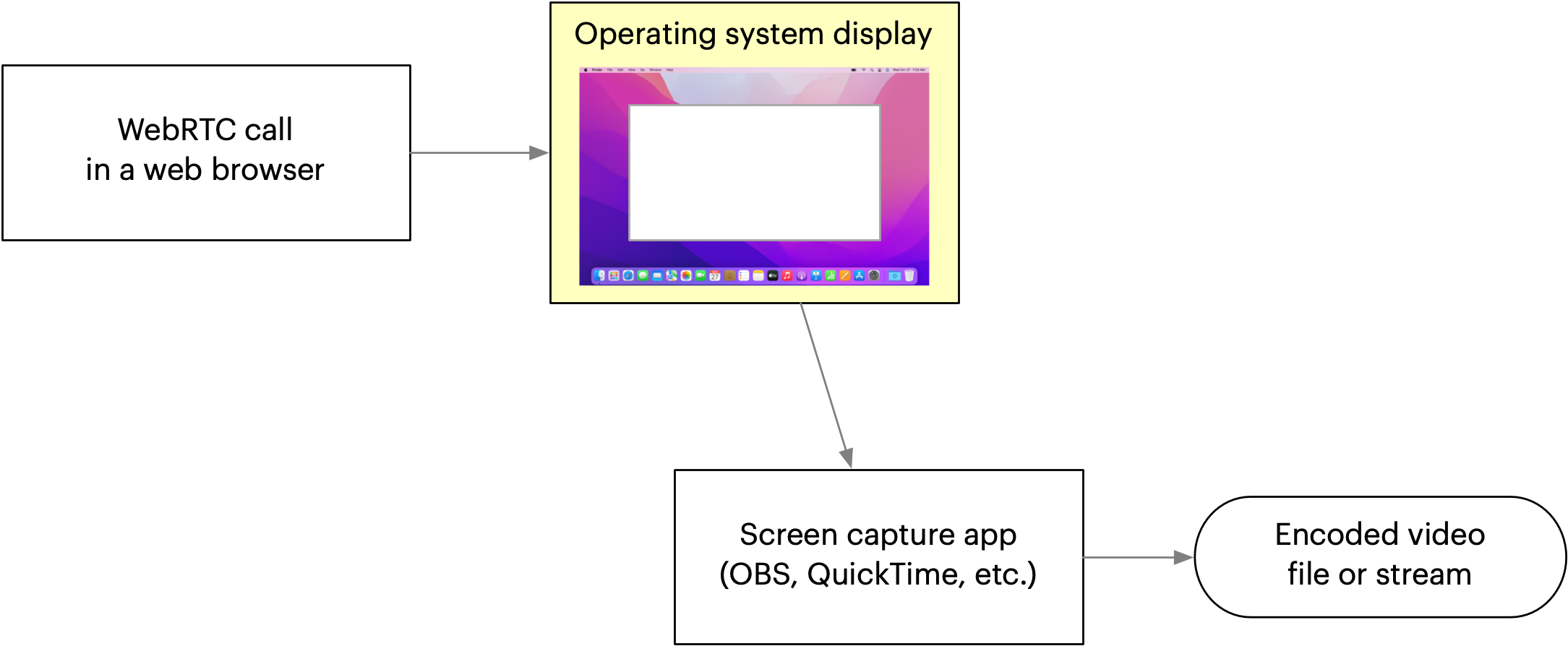
While OBS is a great tool, it’s also pretty complex to use. Unless your users are very technical and already experienced with live streaming, asking them to install and operate OBS is a recipe for disaster. Even with some other simpler desktop application, the core problem remains: the responsibility for recording can’t be delegated to the user if you expect recordings to be reliably available.
We’ll award this solution a 👎 and move on to the next one.
Browser API client recording 🤔
This is a more advanced version of the screen capture idea. Instead of using an external tool to capture the browser’s rendering of the video call as it’s being displayed on the user’s desktop, we could try to capture the video data directly within the web page using JavaScript, and encode it behind the scenes. The user wouldn’t have to configure a separate application.
There are two distinct methods. You could do a screen capture of your app’s window, essentially packaging the previous “ad hoc” method within your app for a slightly more convenient user experience. (This still requires the user to give your app screen capture permissions, so it’s not seamless.) Or you could render the capture in your JavaScript code using MediaStream objects that represent the participant AV streams.
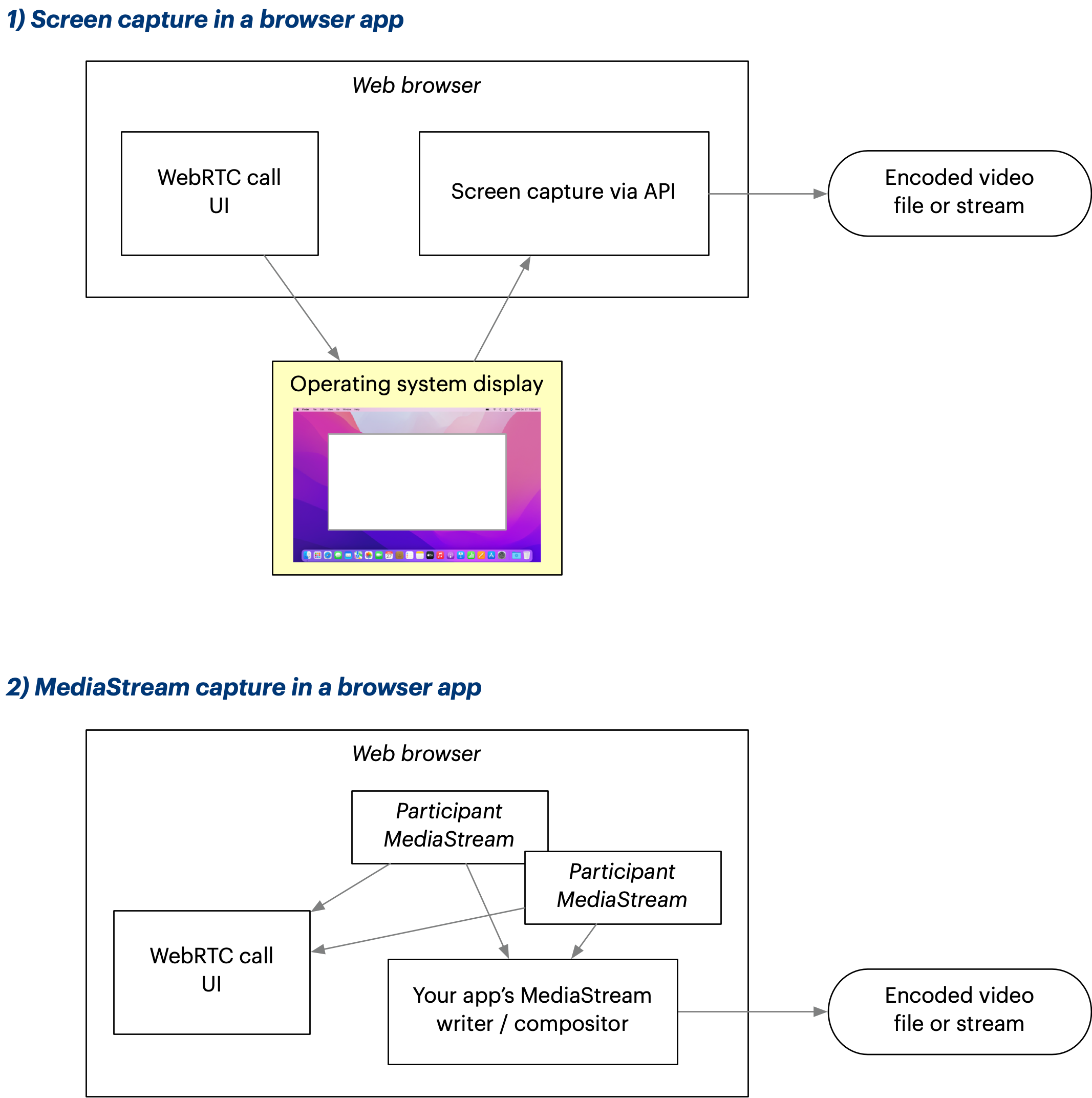
Some of the most relevant browser APIs are:
- MediaRecorder: Lets you record `MediaStream` objects.
- MediaDevices.getDisplayMedia(): Lets you create a `MediaStream` that represents a screen capture. Note that this will need OS-level permissions from the user. On Mac, this means the user has to go into System Preferences to add the permission if not yet set—a substantial usability hurdle.
- Canvas: As an alternative approach to the `getDisplayMedia()` screen capture approach above, you could use an HTML5 canvas to compose your multiple video tracks into a single image for recording. This will give you more control over what exactly gets recorded. Has a `captureStream()` method which lets you turn a canvas into a `MediaStream`, which you could then pass to `MediaRecorder`.
This all sounds pretty good, but you quickly run into a set of challenges:
- Processing and rendering video streams is performance-intensive. Doing this on a user’s computer results in a substantial performance impact, especially if you’re doing HTML canvas rendering. This has real-world consequences as the user’s laptop fans may start running at 100%, things get sluggish in the UI, and so on. The browser media APIs don’t offer a lot of control for performance tuning, so these issues may be hard to debug and fix.
- The available JavaScript APIs are limited and inconsistent between browsers. Options you need may not be universally available, so you’d have to ask users to use a specific browser. (For example the CanvasCaptureMediaStreamTrack API isn’t in Firefox as of this writing.) Even when focusing on a single browser, you may find that the APIs don’t have the kind of format support that could be expected from a video-centric tool. (For example, Chrome may only let you write files in the WebM format, which isn’t as universally supported as MP4.)
- The browser keeps changing and updating automatically. You can’t ask your users to stick with a specific version of Chrome. Unfortunately, as these browser media APIs are quite cutting-edge and not very widely used, they also tend to have bugs. You must diligently test on upcoming browser versions and figure out workarounds and mitigations if a bug is shipping that breaks your application.
- The available ways of capturing the image data aren’t great. Screen capture is inherently fragile. On the other hand, the canvas-based alternative means you’ll have to reimplement the video layout entirely in JavaScript canvas code. This can be feasible if your calls have only a few participants, but appetite for more complex designs tends to grow over time and then you’ll be forever maintaining and updating two versions of your layout code—one for the web UI, another completely separate implementation for the canvas-based recording. Not fun.
Together these can add up to a daunting development challenge. And if you make it work, you’ve still got a fundamental problem: the recording is tied to one user’s computer. If their laptop overheats or runs out of battery, you won’t be getting a recording at all. Despite these significant caveats, this may be the right solution if you don’t have access to server resources so let’s award this a 🤔.
Browser API client raw tracks 👎
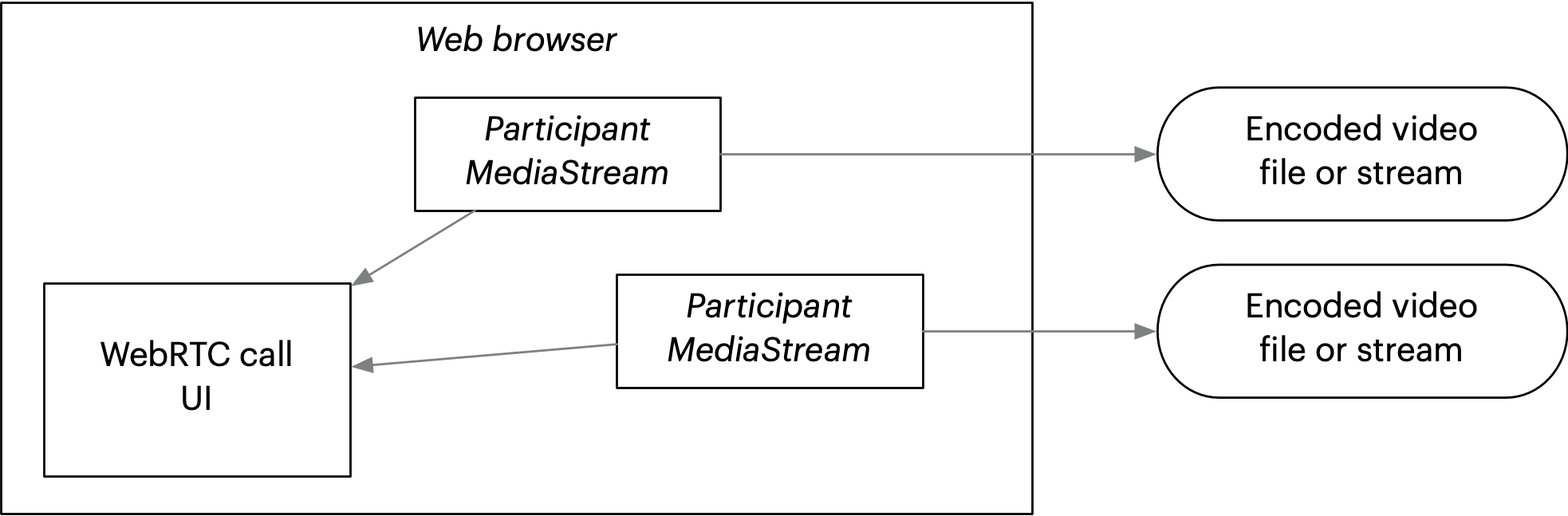
Another take on client-side recording. Instead of a screen capture or a canvas-rendered composite, you could try writing out each participant’s individual `MediaStream` as a separate video file.
The downsides are serious:
- The files would be stored on the user’s local disk. They’d have to edit them into a composite afterwards somehow. Synchronization could be an issue—can you guarantee all the files started recording at the same exact moment?
- Writing many video files simultaneously could easily tax a laptop computer’s disk beyond its ability. We’d have no control over the resolution and bitrate of the files, since this method would record the original data.
This one is clearly a 👎. Let’s move on.
Browser API client recording directly to cloud 🤔
Instead of writing the file locally to disk, how about we upload it immediately to a cloud service from the browser?
This could be done with the MediaRecorder API, but it means we’re adding an even higher workload onto this one client computer. We’d be uploading a second stream simultaneously (assuming the user is already sending their participant video stream to the call.) Upload bandwidth is often limited, so this could lead to frame drops and other disruptive issues.
Again, the problem remains that the recording will be tied to one user’s computer. Nothing gets recorded if that client computer drops out. The only way to break this dependency is to do the recording in the cloud—that is, on a server rather than a client device. (This solution still merits a 🤔 because it’s possible that you don’t have access to server resources.)
Server-rendered live recording using a headless browser 👎
So we’ve decided to move the work to the cloud. Running the recording job on a server will make it bulletproof against users’ network issues, laptops overheating, and so on. Even if all participants drop off temporarily, the recording won’t be interrupted.
Since we already have a rendering of the call running in a browser on users’ computers, the first intuition would be to try to leverage that on the server. A so-called “headless browser” can provide what’s essentially screen capture of the contents of a web page. This is commonly used for rendering images of web pages on servers, in particular for ”headless browser testing” (i.e. automatic validation that the web page UI looks right in its various states during web app development).
There’s a major difference between headless browser testing and WebRTC call capture, though. For test images, it’s not really important if an image takes one second or 0.1 seconds to render. But video output is time-critical—a watchable video file must play at around 20-30fps at the minimum, so the absolute maximum time our headless browser can spend on a frame would be around 50ms (1/20 seconds), and this rate must not fluctuate.
Headless browsers are actually pretty different from the browsers that run on your desktop or mobile device, even if the engine is the same. Client devices practically always have a GPU (graphics processing unit) but servers don’t. Realtime graphics and video in the browser is heavily optimized for the GPU, and the CPU rendering mode is an afterthought, yet that’s the only thing available on a regular server. If we wanted our cloud browser to render WebRTC calls with the same quality and speed as on a desktop, we’d have to provide a GPU on the server.
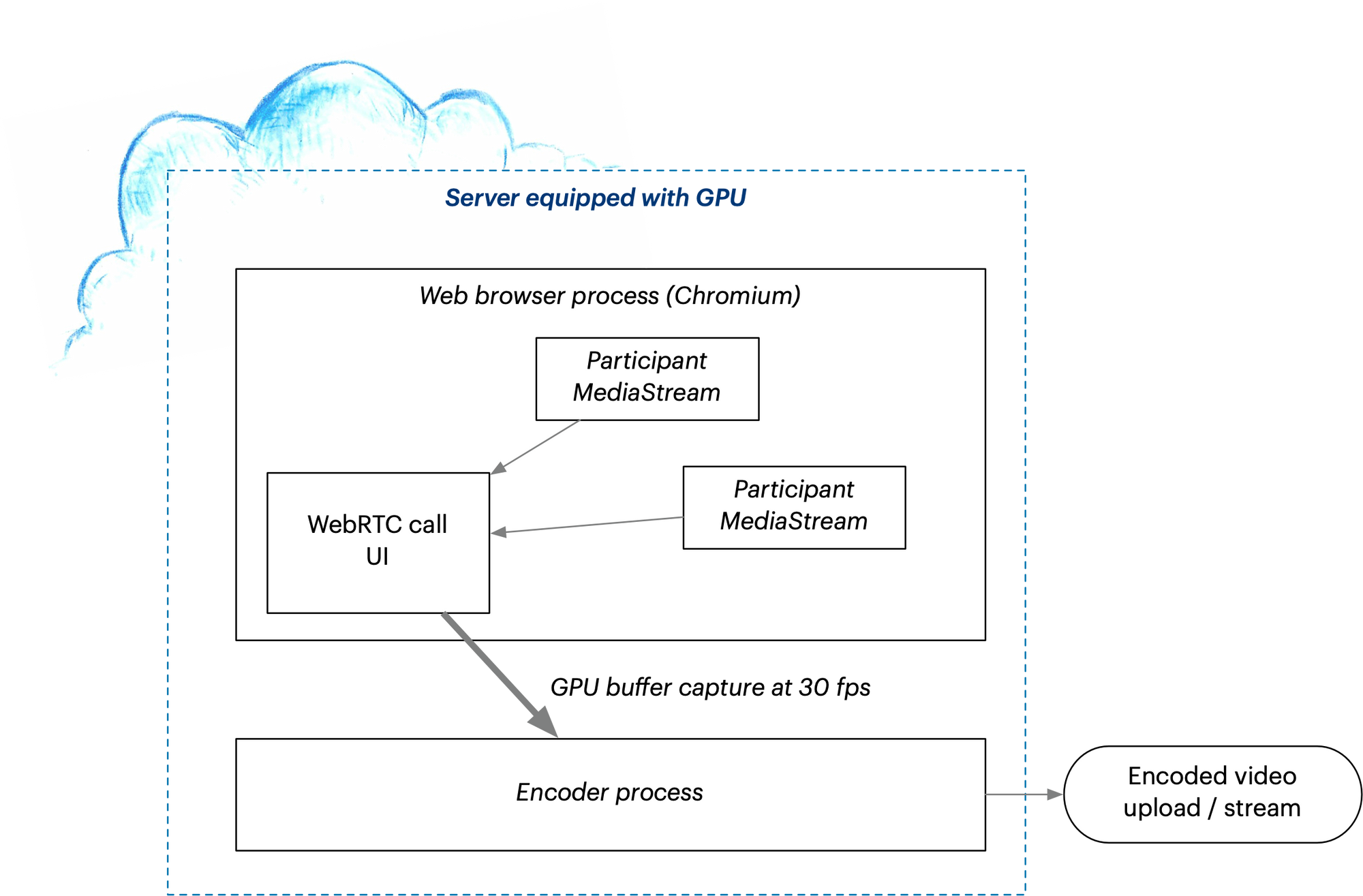
This is where things get tricky. Headless rendering of desktop applications with a GPU is an extremely niche type of server setup. GPU servers are expensive and they’re optimized for machine learning (ML, i.e. pure computing jobs) rather than graphics output using desktop APIs. Doing WebRTC recording this way means you’ll be spending lavishly on expensive ML/AI-oriented cloud servers while trying to make your application see them as regular desktops.
Unless you’re really sure this is where you want to be spending your time and money, this approach merits a 👎. It’s just not practical.
Server-rendered live recording using a media pipeline ⭐️
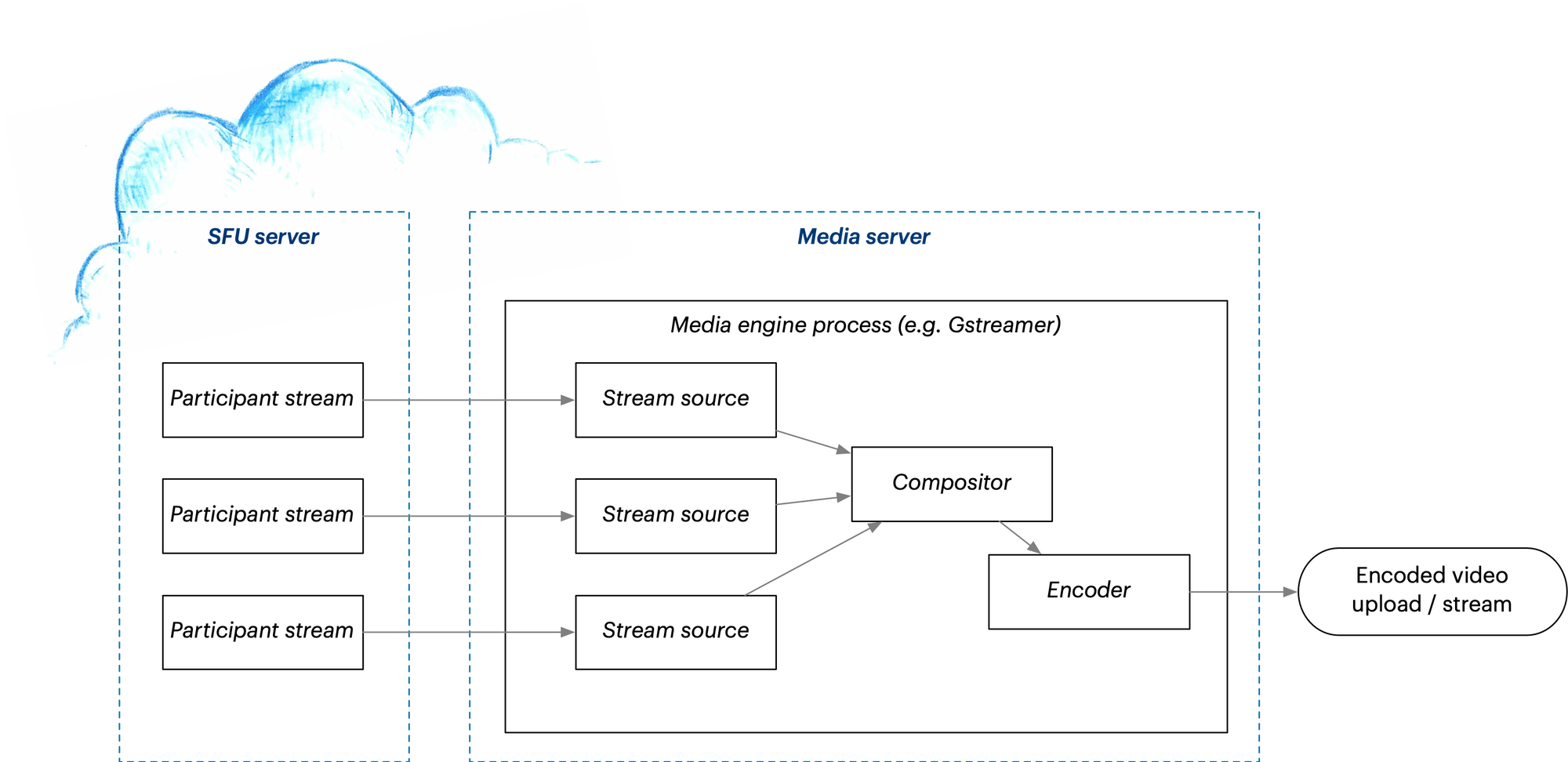
In the previous section we found out that the problem with headless browser capture is, well, the browser itself. It’s optimized for client devices, not servers. If we can accept to give up browser compatibility and instead use some other kind of rendering software on the server, we’ll find our horizons expanded.
Without a browser, it follows that we can’t render the existing web UI as-is. We’ll need to somehow describe the layout and direct the server-based rendering so that our recording will be a close enough match to what participants saw on their client UIs. This unfortunately means extra development effort just to reproduce the layout. You may notice a theme here: We encountered this exact same problem a few sections back when discussing client-side browser APIs for canvas rendering vs. screen capture. Is there any way to avoid maintaining two implementations of the same rendering; one for the web UI, another for the recording? Hold this thought, we’ll come back to it in the last section…
Setting up the server media engine yourself can be a steep challenge. There are really two ways to approach this. You could set up a SFU server, short for Selective Forwarding Unit. This effectively switches your WebRTC call from peer-to-peer into a centralized mode where all video streams go through the SFU server. That server then forwards them to the clients. For calls larger than about five people, you’d usually want to do this anyway because of bandwidth concerns. And since the SFU now has access to all the participants’ streams, it can also produce a recording. At least, that’s the theory—the recording capabilities available directly in SFU servers vary greatly, and the layout options available may be too limited to match your UI.
For more control over the recording, you could use a server dedicated to processing media — i.e. a media server. If your WebRTC call is in peer-to-peer mode, the media server would receive all the streams directly from participants. Or if you’re already using an SFU, the SFU could forward the streams to the media server for rendering. Depending on your requirements, the media server could be implemented with open source technologies like FFmpeg and/or Gstreamer. (You can learn more about Gstreamer as a back-end service and Daily's media infrastructure here.)
Let’s award a ⭐️ here because this really is the most flexible and robust way to do a recording. However due to the complexity of the software stack required, there is a substantial learning curve and cost to building this yourself.
Server-rendered raw tracks ⭐️
At this point, it’s worth again bringing up the option of recording just the raw video tracks during the call, and making a composite afterwards. On a server, you could implement this as part of either of the previously mentioned options (either on an SFU or a media server that receives the peer-to-peer tracks.)
When the call finishes, you would then render out the composite, perhaps using previously mentioned options like FFmpeg or Gstreamer, then upload it to a video hosting/distribution service that will make it available to viewers in the right format. (Raw video files aren’t ready for smooth online playback, they need to be translated into formats like HLS for general viewing.)
Again, questions around participant synchronization and runtime layout description make this a complicated design challenge. Building this solution yourself out of open source components is theoretically possible, but a very tall order. Still, if you need the flexibility of editing the raw tracks after the call, we must award a ⭐️ here as it’s the ultimate in recording configurability.
Code once, render anywhere?
We’ve covered a lot of implementation strategies! Before our conclusion, let’s return to this question that was asked earlier:
“Is there any way to avoid maintaining two implementations of the same rendering; one for the web UI, another for the recording?”
We discussed a number of solutions that focused on capturing a real-time video of a web browser, and the conclusion was that they’re not generally practical or scalable. This left us with the dilemma: how do we make the recording’s visuals match the web UI without writing all the layout code twice?
Daily provides a brand new open source project called Video Component System (VCS) that aims to solve this problem from a different angle.
Instead of capturing the full browser, VCS lets us define the call’s visual layout using a video-oriented set of visual components and APIs. These components can then be rendered in multiple environments: directly on the server for the recording, but also within the web UI.
This means your WebRTC app’s view layer needs to be rearchitected to some degree. Instead of using “raw” HTML video elements to display your participants, you programmatically define the layout in VCS, then use the VCS library to render it as part of your web interface. The VCS library acts like an embedded “black box” for video rendering—on creation you’d attach it to a div element or other container and pass in your MediaStreams.
Rendering then happens independently, as VCS executes the video-specific layout and animation logic (using React as its internal API). There’s a JavaScript API to send commands to the VCS composition. You get to make your own visual components and define what commands can be sent in the context of your app.
Daily offers a server-side implementation of VCS, so you can then render the same layouts into a recording with no extra effort. This solves the problem of maintaining two implementations. You have only one set of layout code written in VCS, and the same code gets embedded both in your client app as well as in the server pipeline.
It’s a “bleeding-edge” solution—for one, VCS is still in beta. But if you have the opportunity to design your WebRTC app’s rendering from scratch, VCS is worth considering because it’s open source and will enable server-side recordings on Daily at no extra engineering cost.
Wrap-up
This completes our survey of the landscape of options for WebRTC recording. Various open source tools and APIs exist for building your own recording solution. This will typically be a large-scale development project unless you’re willing to place very specific requirements on your users, or you can afford the risk of losing recordings due to circumstances like user error or client device technical issues.
Therefore for most applications the better choice may be to “buy, not build”. There are WebRTC platform vendors who provide recording and live streaming as an integrated solution. These include Agora, Vonage, Twilio, and our own platform here at Daily. Our API gives you the choice between server-rendered real-time composition and server-recorded raw tracks, which are the two solutions described previously that were considered best practices.
If you want to learn more about the relevant open source projects and browser APIs, we’ve included many links in the Implementation Strategies section under each approach. And to learn about Daily’s APIs, a great place to start is the “Recording calls” section of our API Guide. You can also learn about VCS in its own guide.
Thanks for reading all the way! If you have any questions, we’d love to hear from you on Discord.
Never miss a story
Get the latest direct to your inbox.