


This is a guest post from Arun Raghavan, who has helped build Daily's media processing infrastructure. This article was originally posted on the Asymptotic blog.
For the last year and a half, we at Asymptotic have been working with the excellent team at Daily. I'd like to share a little bit about what we've learned.
Daily is a real-time calling platform as a service. One standard feature that users have come to expect in their calls is the ability to record them, or to stream their conversations to a larger audience. This involves mixing together all the audio and video from each participant and then storing it, or streaming it live via YouTube, Twitch, or any other third-party service.
As you might expect, GStreamer is a good fit for building this kind of functionality, where we consume a bunch of RTP streams, composite/mix them, and then send them out to one or more external services (Amazon's S3 for recordings and HLS, or a third-party RTMP server server).
I've written about how we implemented this feature elsewhere, but I'll summarise briefly.
This is a slightly longer post than usual, so grab a cup of your favourite beverage, or jump straight to the summary section at end of the post.
Architecture
Participants in a call send their audio and video to a "Selective Forwarding Unit" (SFU) which, as the name suggests, is responsible for forwarding media to all the other participants. The media is usually compressed with lossy codecs such as VP8/H.264 (video) or Opus (audio), and packaged in RTP packets.
In addition to this, the SFU can also forward the media to a streaming and recording backend, which is responsible for combining the streams based on client-provided configuration. Configuration might include such details as which participants to capture, or how the video should be laid out (grid and active participant being two common layouts).
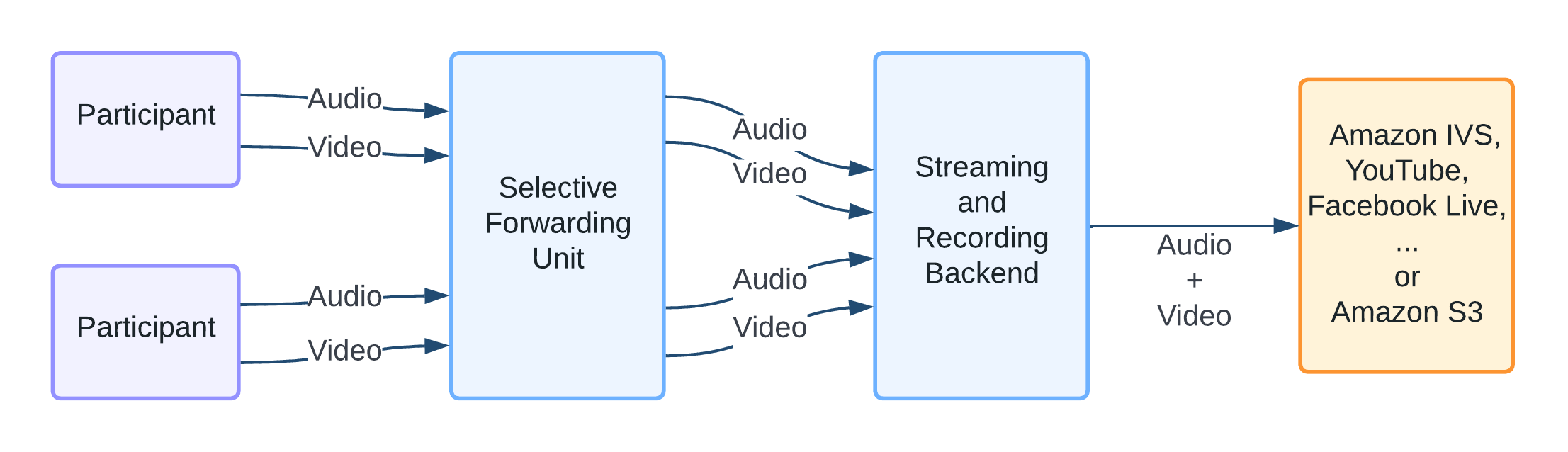
While the illustration itself is static, reality is often messier. Participants may join and leave the call at any time, audio and video might be muted, or screens might be shared. We expect media to come and go dynamically, and the backend must be able adapt to this smoothly.
Let's zoom into the box labelled Streaming and Recording Backend in the illustration above. This is an internal service, which — at its core — is a GStreamer-based application that runs a pipeline like this:
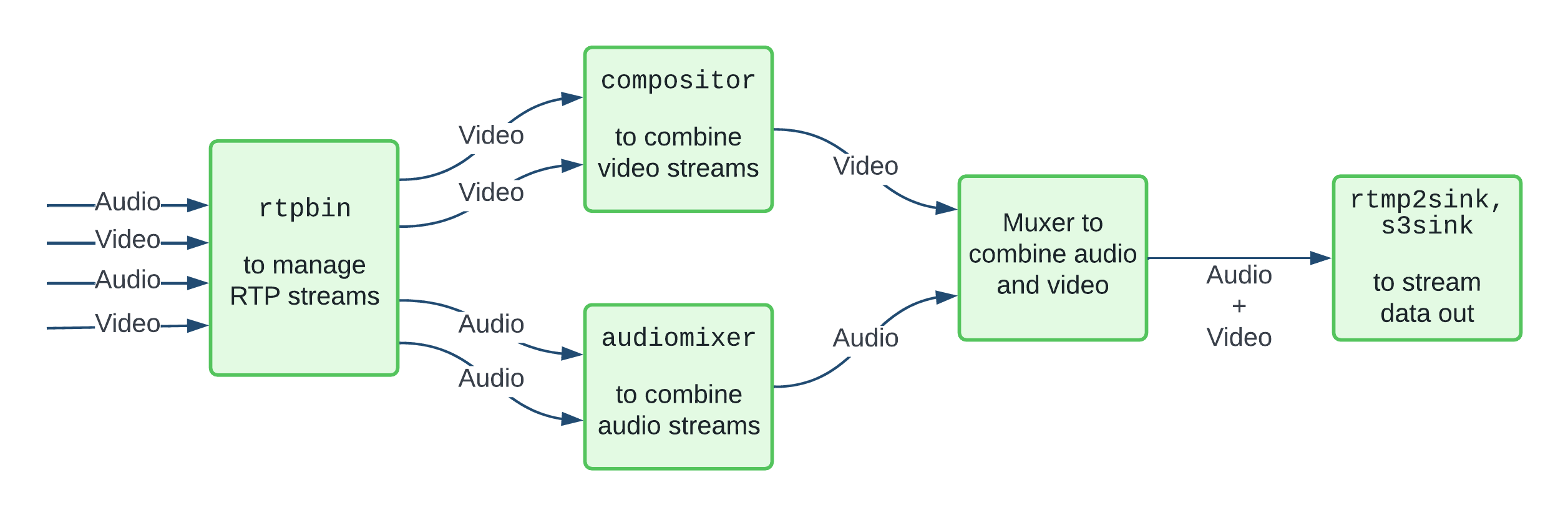
This is, of course, a simplified diagram. There are a number of finer details, such as per-track processing, decisions regarding how we build the composition, and how we manage the set of outputs.
With this architecture in mind, let's dive into how we built this out, and what approaches we found worked well.
Modular output
It should be no surprise to folks familiar with GStreamer that this architecture allows for us to easily expand the set of outputs we support.
We first started with just packaging the stream in FLV and streaming to RTMP with rtmp2sink. Downstream services like YouTube and Twitch could then repackage and stream this to a larger number of users, both in real-time and for watching later.
We then added recording support, which was "just" a matter of adding another branch to the pipeline to package the media in MP4 and stream straight to Amazon S3 using the rusotos3sink (now awss3sink after we rewrote the plugin using the official Amazon Rust SDK).
At a high level, this part of the GStreamer pipeline looks something like:
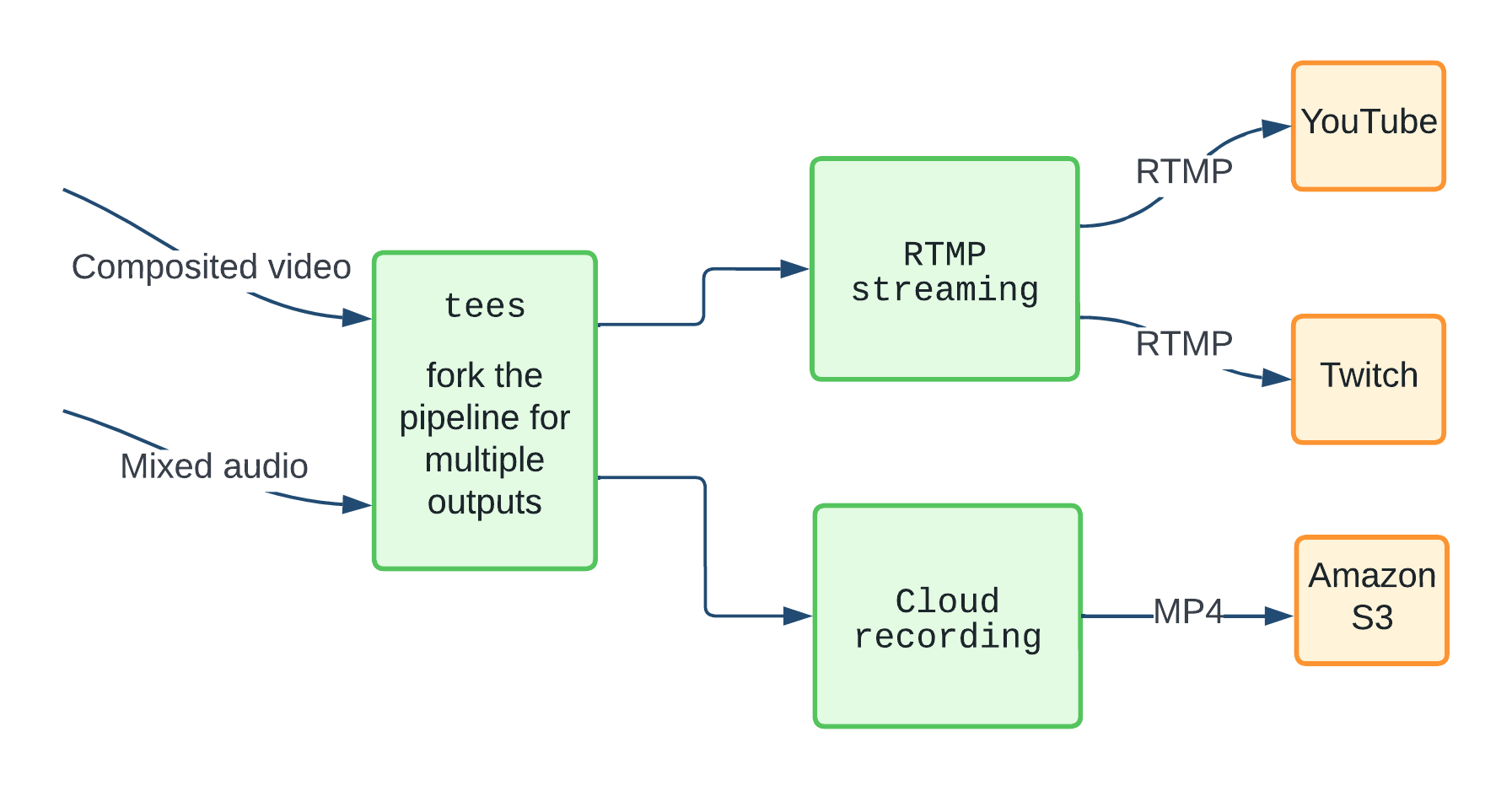
During an internal hackathon, we created an s3hlssink — now upstream — which allows us to write out a single-variant HLS stream from the pipeline directly to an S3 bucket. We also have an open merge request to write out multi-variant HLS directly to S3.
This will provide an HLS output alternative for Daily customers who wish to manage their own media content distribution.
Of course, we can add more outputs as needed. For example, streaming using newer protocols such as SRT would be relatively straightforward.
Complexity management
The GStreamer application started out as a monolithic Python program, for which we have a pretty mature set of bindings. Due to the number of features we wanted to support, and how dynamic they were (the set of inputs and outputs can change at runtime), things started getting complex quickly.
A good way to manage this complexity is to refactor functionality into independent modules. We found that GStreamer bins provide a good way to encapsulate state and functionality, while providing a well-defined control interface to the application. We decided to implement these bins in Rust, for reasons I hope to get into in a future blog post.
For example, we added the ability to stream to multiple RTMP services concurrently. We wrapped this functionality in an "RTMP streaming bin", with a simple interface to specify the set of RTMP URLs being streamed to. This bin then internally manages adding and removing sinks within the running pipeline without the application having to keep track of the details. This is illustrated below.
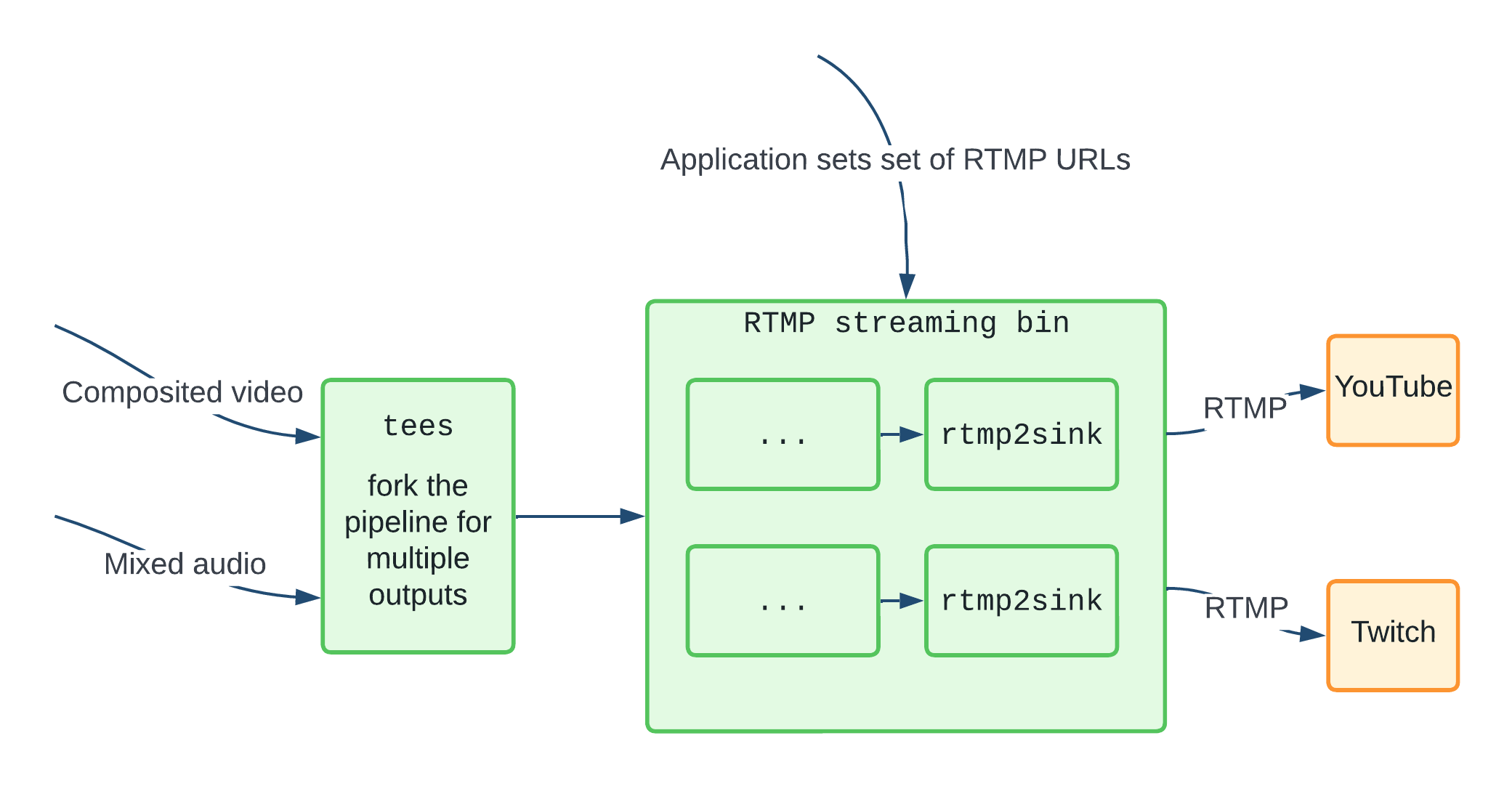
Doing this for each bit of dynamic functionality has made both development and maintenance of the code a lot easier.
Performance and threading
As we started using our pipeline with larger calls, we realised that we did have some performance bottlenecks. When we had more than 9-10 video inputs, the output frame rate would drop from the expected 20fps to 5-10fps. We run the pipeline on a fairly beefy EC2 instance, so we had to dig in to understand what was going on.
We went with a low-tech approach to figure this out, and just used top to give us a sense of the overall CPU consumption. It turned out we were well below 50% of overall CPU utilisation, but still dropping frames.
So we switched top to "threads-mode" (H while it's running, or top -H), to see individual threads' CPU consumption. GStreamer elements provide names for the threads they spawn, which helps us identify where the bottlenecks are.
We identified these CPU-intensive tasks in our pipeline:
- Decoding and resizing input video streams
- Composing all the inputs together
- Encoding video for the output
The composition step looked something like:
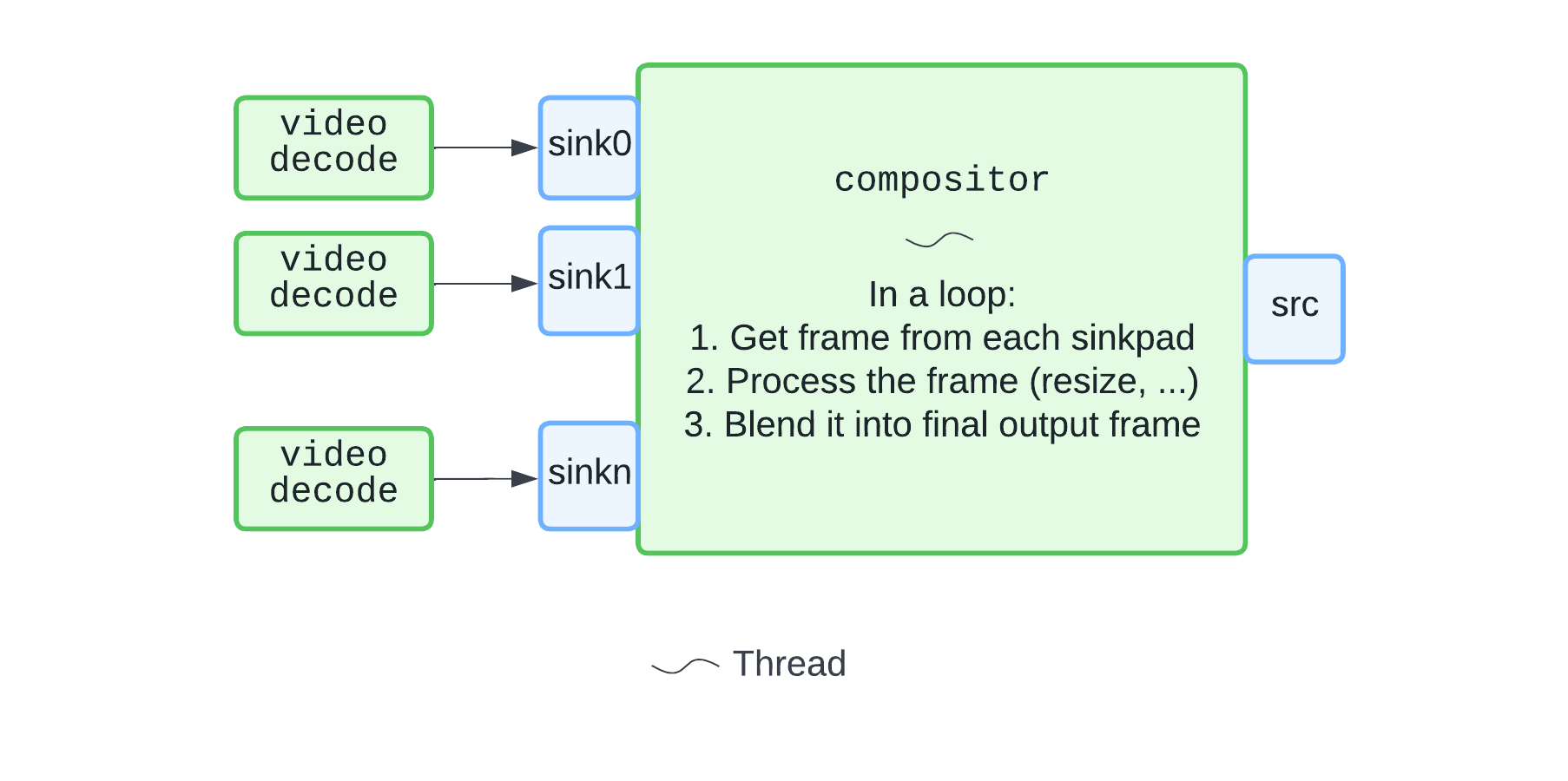
The bottleneck turned out to be in compositor's processing loop. We factored out the expensive processing into individual threads for each video track. With this in place, we're able to breeze through with even 25 video inputs. The new pipeline looked something like:
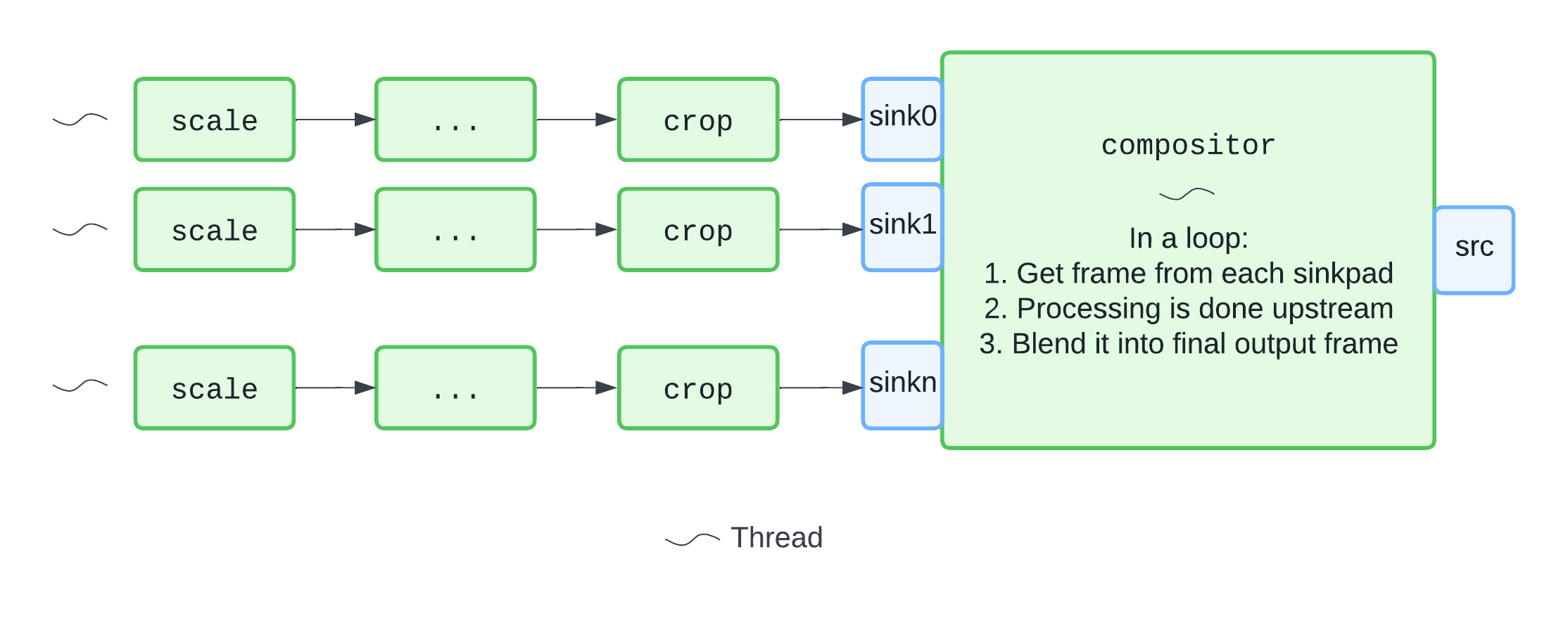
Note: Subsequent to this work, compositor gained the ability to fan out per-input processing into multiple threads. We still kept our manual approach as we have some processing that is not (yet) implemented in compositor. An example of this is a plugin we developed for drawing rounded corners (also available upstream).
The key takeaway here is that understanding GStreamer's threading model is a vital tool for managing the performance of your pipeline.
Buffers and observability
One thing we want to keep in mind from the start is observability — we wanted to be able to easily characterise the performance of a running pipeline, as well as be able to aggregate these statistics to form a view of the health of the system as we added features and made releases.
During the performance analysis I described in the previous section, we found that queue elements provide a good proxy for pipeline health. The queue creates a thread boundary in the pipeline, and looking at fill level and overruns gives us a good sense of how each thread is performing. If a queue runs full and overruns, it means the elements downstream of that queue aren't able to keep up and that's something to look at.
This is illustrated in the figure below. The compositor is not able to keep up in real-time, causing the queues upstream of it to start filling up, while those downstream of it are empty.

We periodically probe our pipeline for statistics from queues and other elements, and feed them into applications logs for analysis and aggregation. This gives us a very useful first point of investigation when problems are reported, as well as a basis for proactive monitoring.
There has been recent work to add a queue tracer to generalise tracking these statistics, which we may be able to adopt and expand.
Summary
Hopefully this post has given you a sense of the platform we have built. In the process, we also set the rails for a very exciting custom composition engine.
To summarise what we learned:
- While I am not an impartial observer, I think using GStreamer helped us ship a large number of features in a relatively brief time
- The ability to dynamically add and remove both inputs and outputs allows us to realise complex use-cases with relative ease
- We manage complexity by encapsulating functionality in bins
- Analysing and tuning performance is very tractable with the right tools and mental model
- Building for observability early on can pay rich dividends
I hope you enjoyed this post. If you think we can help you with your GStreamer needs, do get in touch.
Thank you for your time!
Never miss a story
Get the latest direct to your inbox.