



How many times have you been in a video meeting and figured out who was going to keep notes, keep track of who said what, and come up with action points during the call?
Often, the mental gymnastics of coordinating discussion points and action items hampers productivity and the ability to be truly present in a conversation.
To enhance collaboration, Zoom recently launched a real-time summarization feature enabled by the Zoom AI companion.
Let's take a look at how this works and show you how to build your own AI meeting assistant using best-in-class infrastructure from Daily, Deepgram, and OpenAI.
In this post, Christian and I will show you how we created a real-time LLM-powered meeting assistant with Daily. We’ll cover:
- How to create video meeting sessions with the help of Daily’s REST API.
- How to create an AI assistant bot that joins your meeting with Daily’s Python SDK.
- How to ask your AI assistant questions about the ongoing meeting through OpenAI.
- How to manage the lifecycle of your bot and session.
What we’re building
We’re building an application that call participants can use to
- Access a real-time summary of the video call.
- Pose custom prompts to the AI assistant.
- Generate a clean transcript of the call
- Generate real-time close captions
The demo contains a server and client component. When the user opens the web app in their browser, they’re faced with a button to create a new meeting or join an existing one:
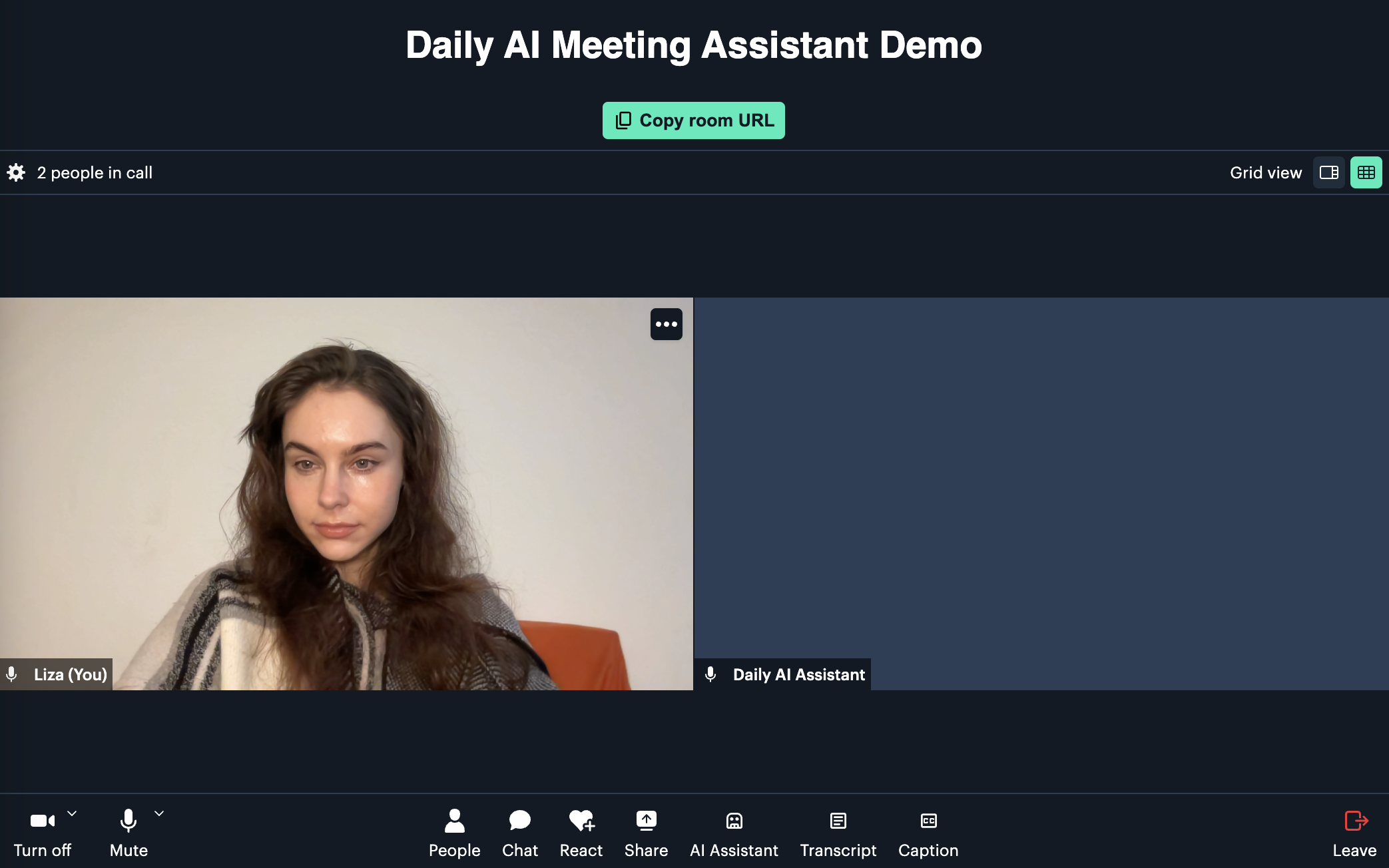
When a meeting is created, the user joins the video call. Shortly thereafter, another participant named “Daily AI Assistant” joins alongside them:
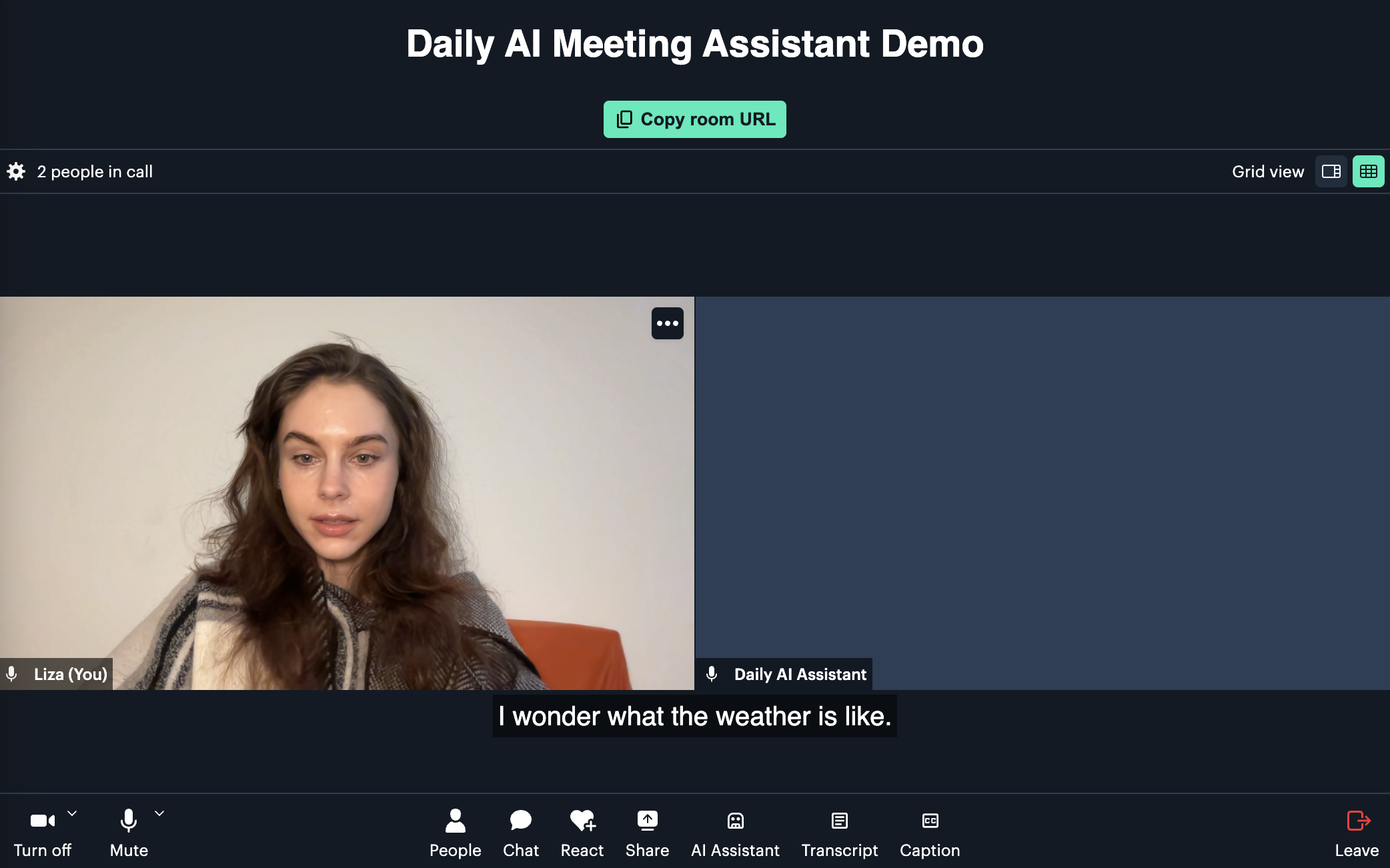
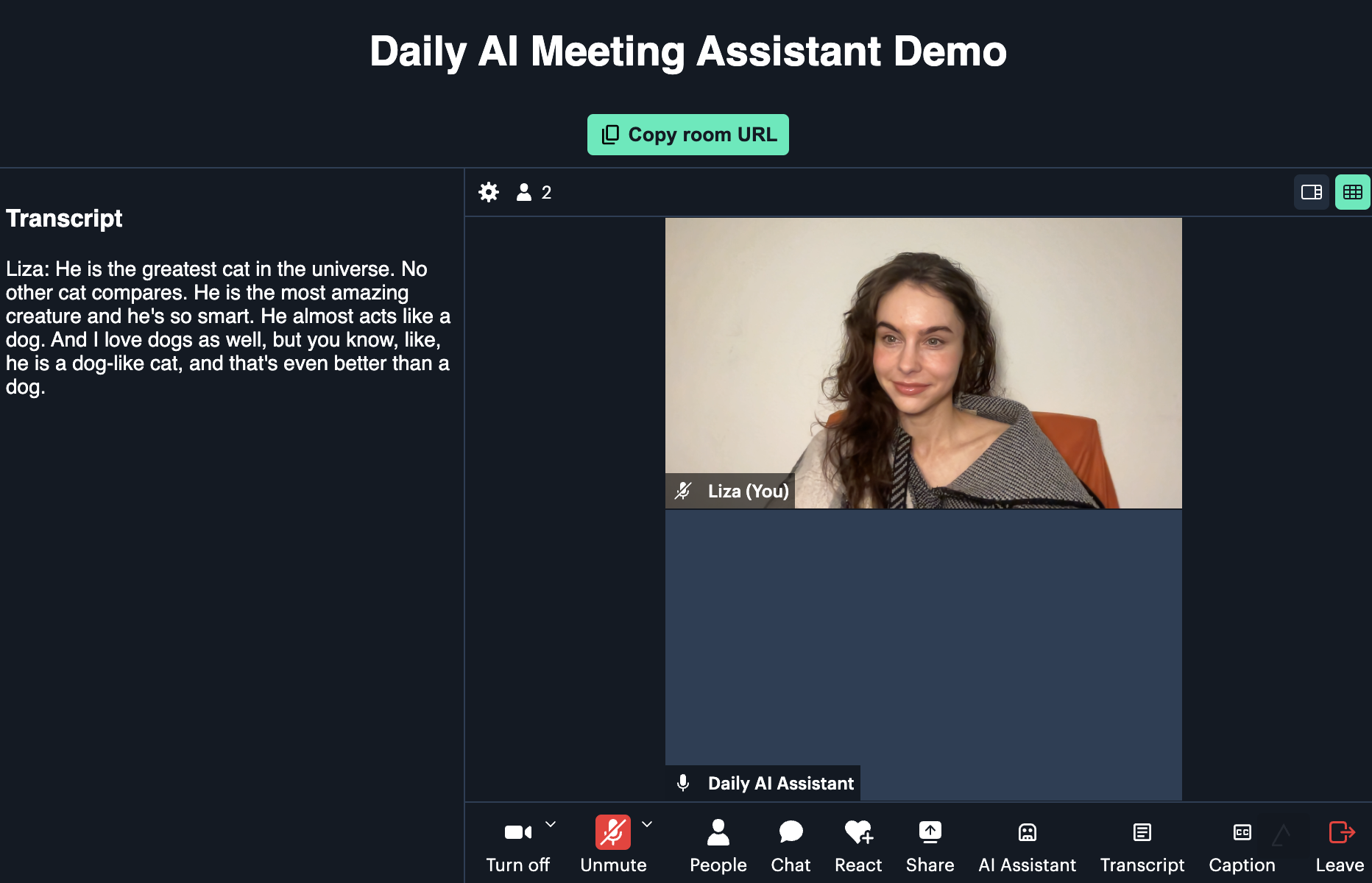
The AI assistant begins transcription automatically, and as you speak with others in the call (or just to yourself), you should see live captions come up:
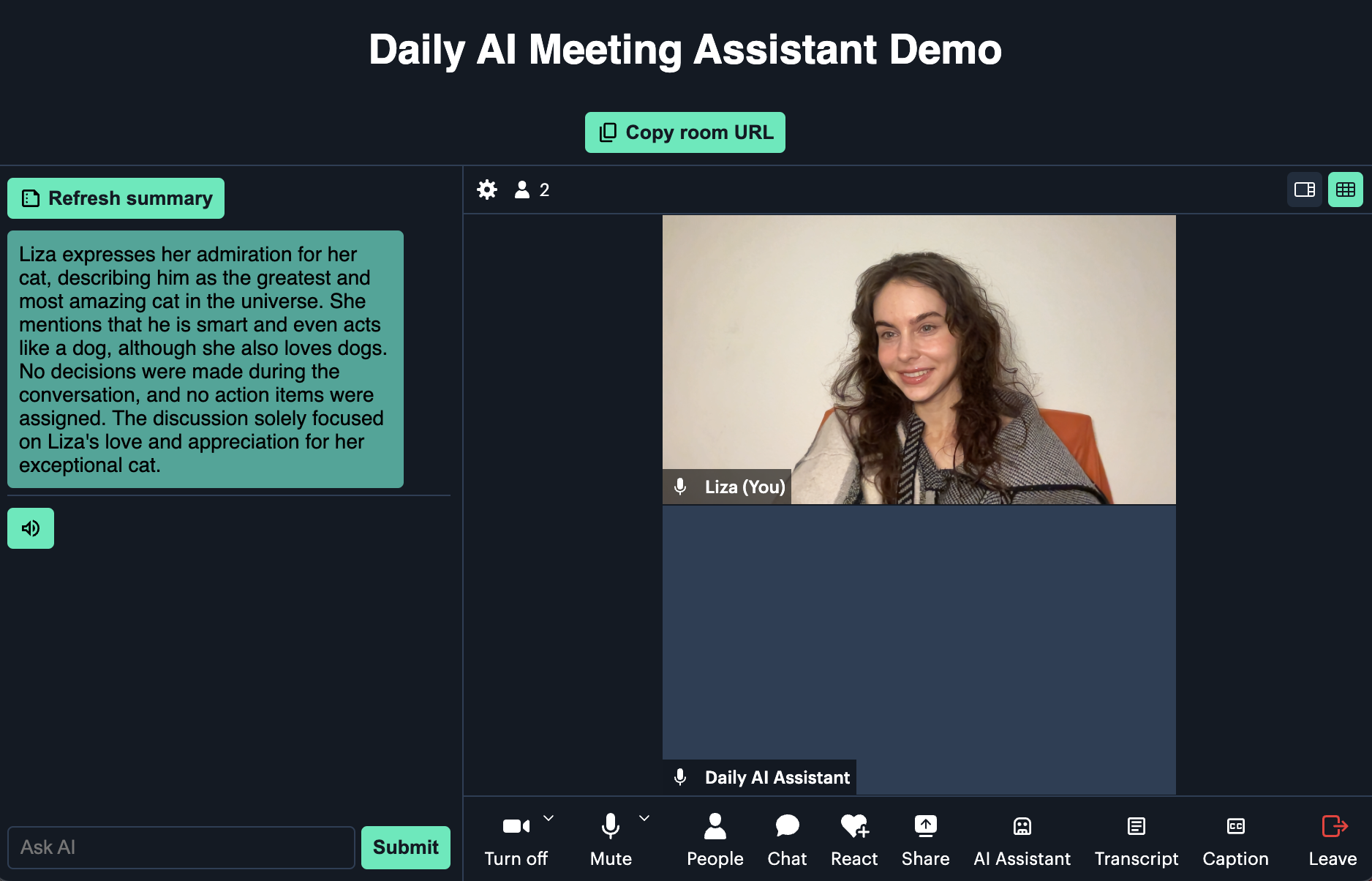
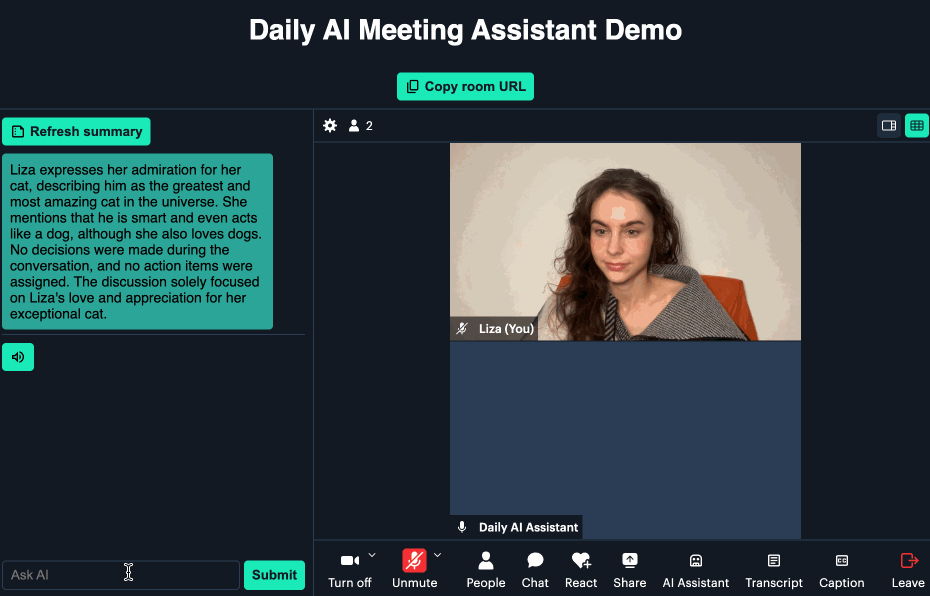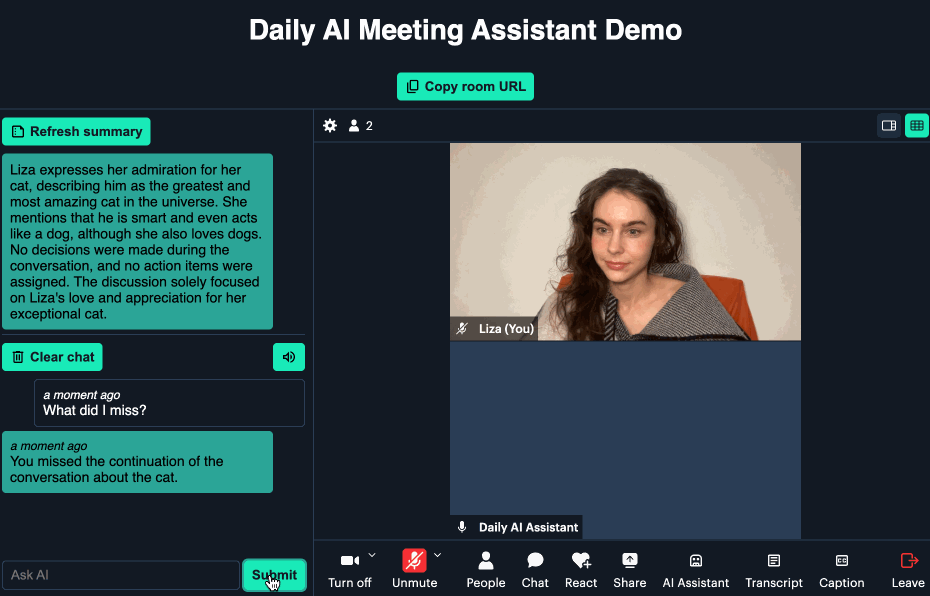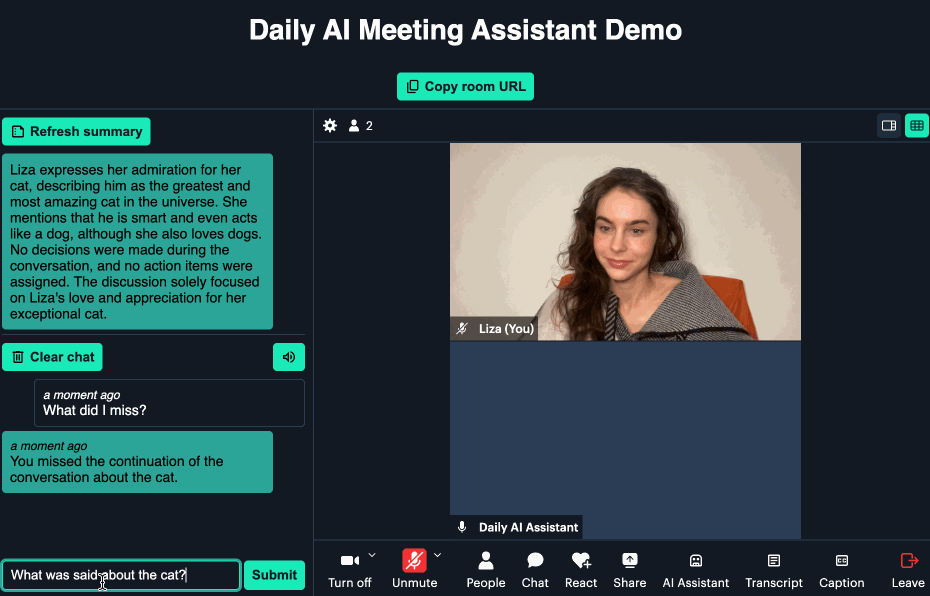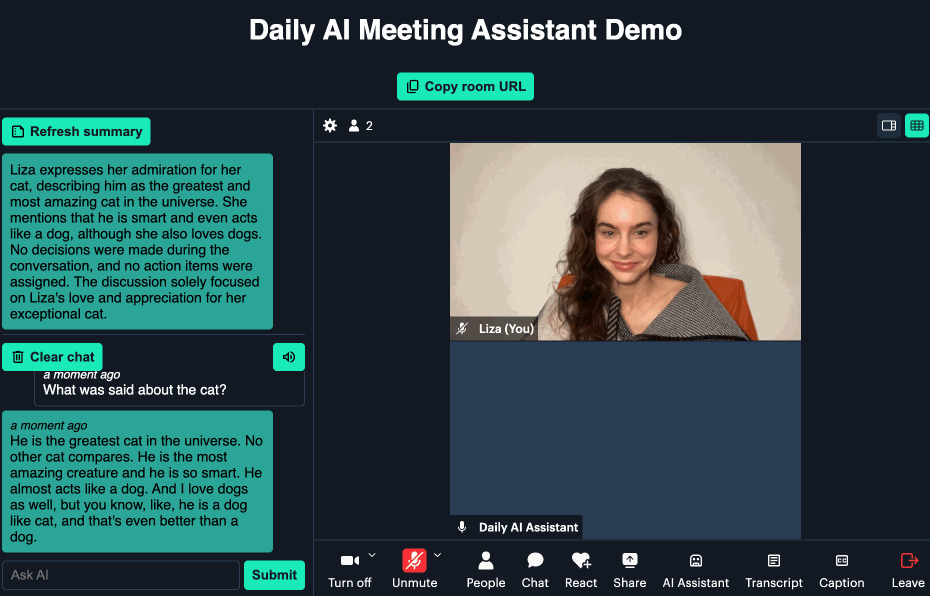
When you or another user wants to catch up on what’s been said so far, they can click on the “AI Assistant” button and request either a general summary or input a custom prompt with their own question:
The user can also request a cleaned-up transcript of the meeting by clicking the “Transcript” button:
Here’s a small GIF showing the custom query feature:
Now, let’s take a look at how to run the application locally.
Running the demo
Prepare the repository and dependencies:
git clone git@github.com:daily-demos/ai-meeting-assistant.git
cd ai-meeting-assistant
git checkout v1.0
python3 -m venv venv
source venv/bin/activate
Inside your virtual environment (which should now be active if you ran the source command above, install the server dependencies and start the server:
pip install -r server/requirements.txt
quart --app server/main.py --debug run
Now, navigate into the client directory and serve the frontend
cd client
yarn install
yarn dev
Open the displayed localhost port in your browser as shown in your client terminal.
With the demo up and running, let’s take a look at the core components.
Core components
Core server components
All the AI operations happen on the server. The core components of the backend are as follows:
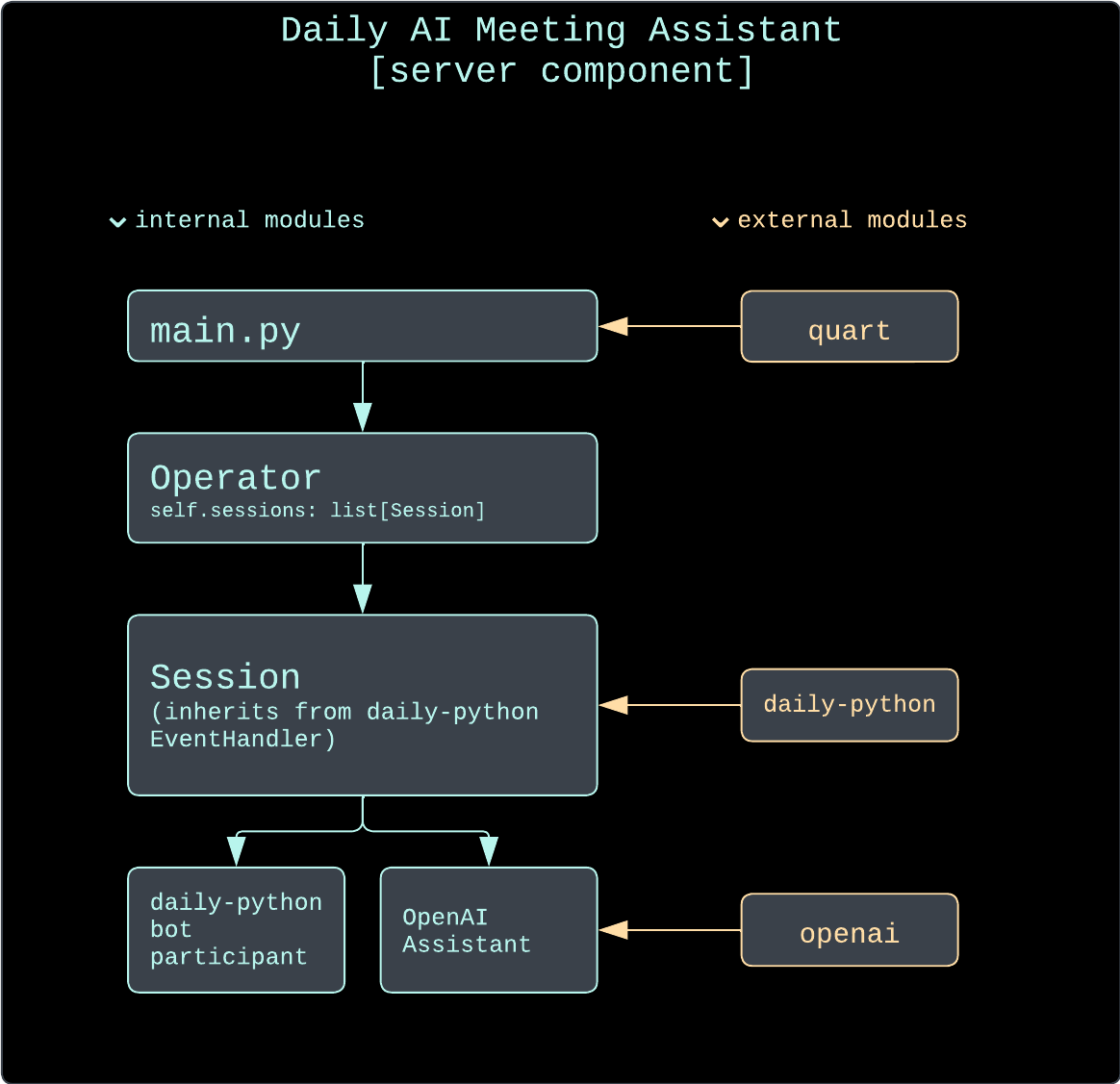
- The
Operatorclass is responsible for keeping track of all assistant sessions currently in progress. It is also the entry point to any of the sessions when a query is made using an HTTP endpoint. - The
Sessionclass encapsulates a single running assistant session. This includes creating a Daily room with Daily’s REST API and instantiating an AI assistant for it, joining the Daily room with adaily-pythonbot, keeping track of any cached summaries, and handling relevant Daily events. TheSessionclass also inherits from thedaily-pythonEventHandler, which enables it to start listening for relevant Daily events (such as meeting joins, app messages, incoming transcription messages, and more) - The
Assistantbase class defines the methods any assistant needs to implement for aSessionto work with it. - The
OpenAIAssistantclass is our example assistant implementation. It handles all interactions with OpenAI and keeps track of the context to send for each prompt.
Core client components
- The
AIAssistantReact component connects to the server, maintains the chat history and processes user input - The
TranscriptReact component maintains a cleaned up transcript of the conversation - The
Appcomponent sets up the Daily iframe, renders theAIAssistantandTranscriptcomponents, configures the custom buttons, and renders closed captions
Now that we have an overview of the core component, let’s dig into the session creation flow.
Server implementation
Session creation
A session is created when the client makes a POST request to the server’s /session endpoint. This endpoint invokes the operator’s create_session() method:
def create_session(self, room_duration_mins: int = None,
room_url: str = None) -> str:
"""Creates a session, which includes creating a Daily room."""
# If an active session for given room URL already exists,
# don't create a new one
if room_url:
for s in self._sessions:
if s.room_url == room_url and not s.is_destroyed:
return s.room_url
# Create a new session
session = Session(self._config, room_duration_mins, room_url)
self._sessions.append(session)
return session.room_url
Above, the operator first checks if a session for the provided room URL (if any) already exists. If not, or if an existing room URL has not been provided, it creates a Session instance and then appends it to its own list of sessions. Then, it returns the Daily room URL of the session back to the endpoint handler (which returns it to the user).
A few things happen during session creation. I won’t show all the code in-line, but provide links to the relevant parts below:
- If no Daily room URL has been provided, a room is created, along with an accompanying owner meeting token with which our assistant bot will join the room later.
- If a Daily room URL had been provided to the
/sessionendpoint, the session instance retrieves information about the given room and initializes a session using that room instead of creating a new one. - An
OpenAIAssistantinstance is created. There is one assistant per session. - In a new thread, the session begins to poll the room’s presence data, monitoring how many people are in the room, since there’s no point having the assistant hang around a room when it’s empty.
- When there’s at least one person in the room, the session creates a Daily call client and uses it to join the room.
- Once the session has connected to the Daily room, the
on_joined_meeting()completion callback is invoked. At this point, the session starts transcription within the room and sets its in-call user name to “Daily AI Assistant”.
The client will have received a response with the new Daily room URL right after step 1 above, meaning it can go ahead and join the room in its own time.
Now that we know how a session is created, let’s go through how transcription messages are handled.
Handling transcription events and building the OpenAI context
Daily partners with Deepgram to power our built-in transcription features. Each time a transcription message is received during a Daily video call, our EventHandler (i.e., the Session class) instance’s on_transcription_message() callback gets invoked.
Here, the Session instance formats some metadata that we want to include with each message and sends it off to the assistant instance:
server/call/session.py:
def on_transcription_message(self, message):
"""Callback invoked when a transcription message is received."""
user_name = message["user_name"]
text = message["text"]
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
metadata = [user_name, 'voice', timestamp]
self._assistant.register_new_context(text, metadata)
The self._assistant.register_new_context() method then takes the text and metadata information and formats it into a single OpenAI ChatCompletionUserMessageParam, which it adds to its context collection:
server/assistant/openai_assistant.py:
def register_new_context(self, new_text: str, metadata: list[str] = None):
"""Registers new context (usually a transcription line)."""
content = self._compile_ctx_content(new_text, metadata)
user_msg = ChatCompletionUserMessageParam(content=content, role="user")
self._context.append(user_msg)
The final context message will look something like this:
[Liza | voice | 2023-11-13 23:24:10] Hello! I’m speaking.
Now that we know how transcription messages are being registered in our assistant implementation context, let’s take a look at how to actually use them by querying the assistant.
Using the OpenAI assistant
There are two primary ways to use the configured AI assistant: to generate a generic meeting summary or to issue custom queries. Both of these types of query can be performed through HTTP endpoints or "app-message” events.
Querying entry points: HTTP and ”app-message”
To see the querying entry points implemented for the HTTP flow, refer to the /summary and /query routes. When a request is made to one of these routes, the Operator instance is instructed to find the relevant Session instance and invoke its query_assistant() method.
To see the querying entry point implemented for the ”app-message” flow, refer to the on_app_message() method within the Session class.
If the assistant is queried through HTTP requests, the answer will be sent back directly in the server’s response. If it’s queried through ”app-message” events, the response will be transmitted back through the send_app_message() call client method provided by daily-python.
Custom query or general summary
There are two types of queries an end user can make to the AI assistant:
- The user can ask for a “general summary” of the meeting.
- The user can pass in a custom query with their own question.
A “general summary” is what is produced by default if no custom query is provided to the assistant. Here’s the default prompt we opted to use to generate this general summary:
_default_prompt = ChatCompletionSystemMessageParam(
content="""
Based on the provided meeting transcript, please create a concise summary. Your summary should include:
1. Key discussion points.
2. Decisions made.
3. Action items assigned.
Keep the summary within six sentences, ensuring it captures the essence of the conversation. Structure it in clear, digestible parts for easy understanding. Rely solely on information from the transcript; do not infer or add information not explicitly mentioned. Exclude any square brackets, tags, or timestamps from the summary.
""",
role="system")
When the session’s query_assistant() method is invoked without a custom query, it will produce a general summary by default. A general summary will be regenerated no more than once every 30 seconds. If a summary that is newer than 30 seconds already exists, the session will just return that instead of sending a prompt to OpenAI again:
def query_assistant(self, recipient_session_id: str = None,
custom_query: str = None) -> [str | Future]:
"""Queries the configured assistant with either the given query, or the
configured assistant's default"""
want_cached_summary = not bool(custom_query)
answer = None
# If we want a generic summary, and we have a cached one that's less than 30 seconds old,
# just return that.
if want_cached_summary and self._summary:
seconds_since_generation = time.time() - self._summary.retrieved_at
if seconds_since_generation < 30:
self._logger.info("Returning cached summary")
answer = self._summary.content
# The rest of the method below…
If we don’t want a general summary or a cached summary doesn’t exist yet, the session goes ahead and queries OpenAI:
def query_assistant(self, recipient_session_id: str = None,
custom_query: str = None) -> [str | Future]:
# …Previously-covered logic above…
# If we don't have a cached summary, or it's too old, query the
# assistant.
if not answer:
self._logger.info("Querying assistant")
try:
answer = self._assistant.query(custom_query)
# If there was no custom query provided, save this as cached
# summary.
if want_cached_summary:
self._logger.info("Saving general summary")
self._summary = Summary(
content=answer, retrieved_at=time.time())
except NoContextError:
answer = ("Sorry! I don't have any context saved yet. Please try speaking to add some context and "
"confirm that transcription is enabled.")
# Rest of the method below…
Above, we query the assistant and then, if relevant, cache the returned summary for subsequent returns. If we encounter a NoContextError, it means a summary or custom query was requested before any transcription messages have been registered, so a generic error message is returned.
Finally, the retrieved answer is sent to the client either in the form of a string (which then gets propagated to and returned by the relevant request handler) or an ”app-message” event:
def query_assistant(self, recipient_session_id: str = None,
custom_query: str = None) -> [str | Future]:
# …Previously-covered logic above…
# If no recipient is provided, this was probably an HTTP request through the operator
# Just return the answer string in that case.
if not recipient_session_id:
return answer
# If a recipient is provided, this was likely a request through Daily's app message events.
# Send the answer as an event as well.
self._call_client.send_app_message({
"kind": "assist",
"data": answer
}, participant=recipient_session_id, completion=self.on_app_message_sent)
Now that we know how sessions are created and queried, let’s look at the final important piece of the puzzle: ending a session.
Ending a session
This demo creates sessions which expire in 15 minutes by default, but this expiry can be overridden with a room_duration_mins /session request parameter. Once a room expires, all participants (including the assistant bot) will be ejected from the session.
But what if users are done with a session before it expires, or the server as a whole is shut down? It is important to properly clean up after each session. And the most important thing to keep in mind is that you must explicitly tell your daily-python bot to leave the room unless you want it to hang around indefinitely.
In this demo, there’s no point having the bot hanging around and keeping the session alive if there is no one in the actual Daily room. What’s there to assist with if there’s no one actually there?! So, our rules for the session are as follows:
- An assistant bot only joins the room when there is at least one present participant already there.
- The
Sessioninstance waits up to 5 minutes for at least one person to show up after creating a Daily room. If no one shows up within that time, the session is flagged as destroyed and will eventually be cleaned up by theOperatorinstance - Once a session has started and a bot has joined, the session pays attention to participants leaving the call. When no more participants are present, a shutdown process begins. The session waits for 1 minute before completing this process, allowing some time for users to rejoin and continue the session.
- Once the 1-minute shutdown timer runs out, the session instructs the assistant bot to leave the room with the call client’s
leave()method. - Once the bot has successfully left the room (confirmed via invocation of our specified leave callback, the session is flagged as destroyed.
- Every 5 seconds, the
Operatorinstance runs an operation which removes any destroyed sessions from its session collection.
And now our cleanup is complete!
Considerations for production
Rate limiting and authorization
One important thing to consider is that this demo does not contain any rate limiting or authorization logic. The HTTP endpoints to query any meeting on the configured Daily domain can be freely used by anyone with a room URL and invoked as many times as one wishes. Before deploying something like this to production, consider the following:
- Who should be allowed to query information about an ongoing meeting?
- How often should they be permitted to do so?
You can ensure that only authorized users have access to meeting information by either gating it behind your own auth system or using Daily’s meeting tokens. A meeting token can be issued on a per-room basis, either by retrieving one from Daily’s REST API or self-signing a token yourself using your Daily API key. Meeting tokens can also contain claims indicating certain privileges and permissions for the holder. For example, you could make it so that only a user with an owner token is able to send custom queries to the assistant, but users with regular tokens are able to query for a general summary. Read more about obtaining, handing, and validating meeting tokens in your application.
Context token limits
By default, the backend uses OpenAI’s GPT 3.5 Turbo model, which can handle a context length of 4000 tokens. You can specify another model name in the OPENAI_MODEL_NAME environment variable, keeping potential tradeoffs in mind. For example, GPT 4 Turbo supports a whopping 120,000-token context, but we’ve found it to be more sluggish than 3.5 Turbo.
Additionally, consider optimizing the context itself. We went for the most straightforward approach of storing context in memory exactly as it comes from Daily’s transcription events, but for a production use case you may consider deprecating older context if appropriate, or replacing older context with previously generated, more concise summary output. The approach depends entirely on your specific use case.
Client implementation
With a server being set up and ready to run your personal AI assistant, it only requires a client to utilize the endpoints we’ve outlined before and incorporate them into a slick client application. We’ll be using Daily Prebuilt to take care of all the core functionality for the video call which allows us to keep the code of this demo small and focussed on integrating the AI assistant’s server component.
Setting up the app
We’ll build the demo app on top of Next.js, but it can be built using any JavaScript framework or no framework at all.
The main application is rendered on the index page route and renders the App component. The App component instantiates the Daily iframe and creates the server session. A Daily room URL can be provided through an input field or through a url query parameter and will make sure that the bot participant joins the given room. When no URL is provided, the client will join the room URL that is returned from the /create-session endpoint.
The app doesn’t send HTTP requests to the Python server directly: instead HTTP requests are routed through Next.js API routes to circumvent potential CORS issues.
In setting up the Daily iframe we’ll also mount the AIAssistant and Transcript components and configure custom buttons to:
- toggle the AI Assistant view
- toggle the Transcript view
- toggle on-screen captions
As of writing this, Daily Prebuilt doesn’t support on-screen captions out of the box, but having captions rendered on screen helps comprehend how the spoken words were transcribed to text. Eventually the transcriptions make the context for the AI Assistant.
Building the AI Assistant UI
The AI Assistant is rendered next to the Prebuilt iframe. The AIAssistant component renders a split-view consisting of a top area for a meeting summary and bottom area with a simplified chat-like UI.
The Summary button is connected to the /summary endpoint on the Python server. Once clicked, it will request a summary from the server and render it in the top area of the AIAssistant view. Since the timing can vary, depending on whether the server returns a cached response or generates a new summary, we’ll disable the button while a summary is being fetched.
The input field and Submit button allow users to ask individual questions and connect to the /query endpoint. Similarly to the Summary button, the input field and Submit button are disabled while a query is being processed. The user’s question and the assistant’s answer are then rendered in the message stream.
Finally the Transcript component automatically requests a cleaned up transcript using the /query endpoint. The component updates the rendered transcript every 30 seconds, in case new transcription lines were captured. When receiving transcript lines from deepgram, sentences might be broken into fragments. Providing a cleaned up transcript drastically improves the readability for the end-user. The Transcript component is technically always rendered to make sure that the useTranscription hook always receives the transcription app data events in order to maintain the cleaned up transcript state. We hide the component using display: none.
Closing the cycle
When the meeting ends, the Daily Prebuilt iframe is being torn down and the user is returned to the start screen.
Conclusion
In this post, Christian and I showed you how to build your own live AI-powered meeting assistant with Daily and OpenAI. If you have any feedback or questions about the demo, please don’t hesitate to reach out to our support team or head over to our Discord community.
Never miss a story
Get the latest direct to your inbox.