

I’ve talked before on this blog about the surprising complexities of recording WebRTC calls. Today I’d like to discuss the case of web page recording more widely.
The solutions explained here also have relevance to web application UI architecture in general. I’m going to show you some ideas for layered designs that enable content-specific acceleration paths. This is something web developers typically don’t need to think about very often, but it can be crucial to unlocking high performance. Examining the case of web page recording can help to understand why.
Daily’s video rendering engine VCS is designed for this kind of layered architecture, so you can apply these ideas directly on Daily’s platform. At the end of this post, I’ll talk more about VCS specifically and how web page recording fits into the picture.
Three types of web capture
First we should define more precisely what’s meant by “recording”. We’re talking about using a web browser application running on a server in a so-called headless configuration (i.e., no display or input devices are connected).
With such a setup, there are several ways to capture content from a web page:
- Extracting text and images, and perhaps downloading embedded files like video. This is usually called scraping. The idea is to capture only the content that is of particular interest to you, rather than a full snapshot of a web application’s execution. Crawling, as done by search engines, is an adjacent technique (traditionally crawlers didn’t execute JavaScript or produce an actual browser DOM tree, but today a lot of content is in web applications that can’t be parsed without).
- Taking screenshots of the browser at regular intervals or after specific events. This is usually in the context of UI testing, and more generally, falls under the umbrella of browser automation. You might use the produced screenshots to compare them with an expected state (i.e., a test fails if the browser’s output doesn’t match). Or the screenshots could be consumed by a “robot” that recognizes text content, infers where UI elements are located, and triggers events to use the application remotely.
- Capturing a full A/V stream of everything the browser application outputs, both video and audio, and encoding it into a video file. This is effectively a remote screen capture on a server computer that doesn’t have a display connected.
In this post, I’ll focus on the last kind of headless web page recording: capturing the full A/V stream from the browser. Because we’re capturing the full state of the browser’s A/V output, it is much more performance-intensive than the more commonplace scraping or browser automation.
Those use cases can get away with capturing images only when needed. But for the A/V stream, the browser’s rendering needs to be captured at a stable 30 frames per second. Everything that can happen within the web page needs to be included: CSS animations and effects, WebRTC, WebGL, WebGPU, WebAudio, and so on. With the more common browser automation scenario, you have the luxury of disabling browser features that don’t affect the visual state snapshots you care about. But this is not an option for remote screen capture.
So why would you even want this? Clearly it’s more of a niche case compared to scraping and browser automation, which are massively deployed and well understood. The typical scenario for full A/V capture is that you have a web application with rich content like video and dynamic graphics, and you want to make a recording of everything that happens in the app without requiring a user to activate screen capture themselves. When you’ve already developed the web UI, it seems like the easy solution would be to just capture a screen remotely. Surely that’s a solved problem because the browser is so ubiquitous…?
Unfortunately it’s not quite that simple. But before we look at the details, let’s do a small dissection of an example app.
What to record in a web app
The following UI wireframe shows a hypothetical web-based video meeting app, presumably implemented on WebRTC:
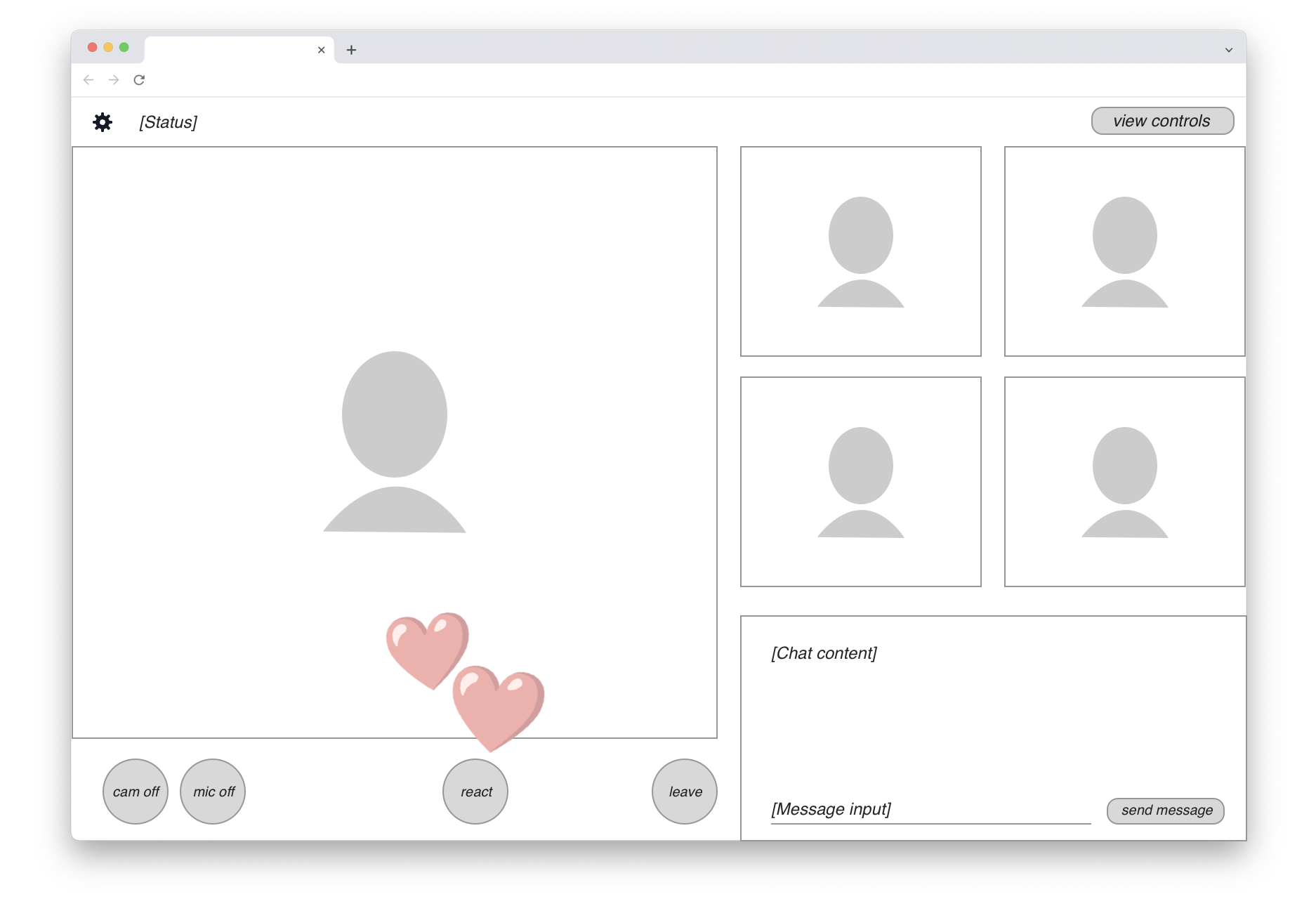
There are up to five participant video streams displayed. In the bottom-right corner, a live chat view is available to all users. In the bottom-left row, we find standard video call controls and a “React” button that lets users send emojis. When that happens, an animated graphic is rendered on top of the video feed (shown here by the two floating hearts).
Recording a meeting like this means you probably want a neutral viewpoint. In other words, the content shown in the final recording should be that of a passive participant who doesn’t have any of the UI controls.
The content actually needed for the headless recording is marked with a blue highlight in this drawing:
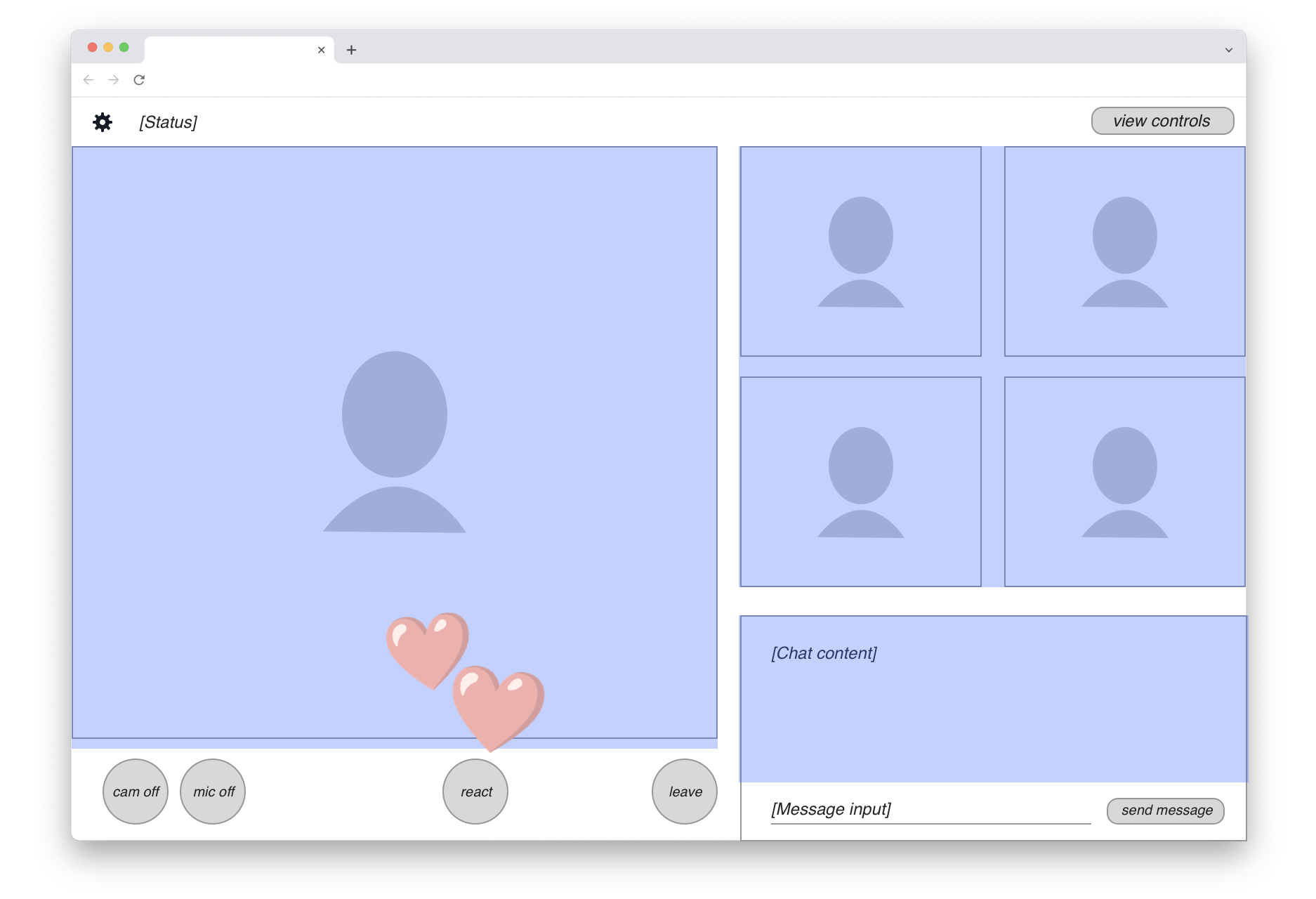
We can see that the majority of UI elements on the page should actually be excluded from the recording. So in fact, the “web page recording” we seek isn’t quite as straightforward as just running a screen capture. We’ll clearly need to do some front-end engineering work to create a customized view of the application for the recording target.
Assuming this development work is done, where can we then run these remote screen capture jobs? Here is the real rub.
Competing for the hottest commodity in tech
The web browser offers a very rich palette of visual capabilities to application developers. CSS includes animations, transitions, 3D layer transformations, blending modes, effects like Gaussian blur, and more — all of which can be applied together. On top of that we’ve got high-performance rendering APIs like Canvas, WebGL and today also WebGPU. If you want to capture real web apps at 30 fps, you can’t easily pick a narrow subset of the capabilities to record. It’s all or nothing.
Intuitively the browser feels like a commodity application because it runs well on commodity clients like cheap smartphones, low-end laptops, and other devices. But this is achieved by extensive optimization for the modern client platform. The browser relies on client device GPUs for all of its visual power. A mid-range smartphone that can run Chromium with the expected CSS bells and whistles has an ARM CPU and an integrated GPU, both fully available to the browser application.
Commodity servers are a very different hardware proposition. An ordinary server has a fairly high-end Intel/AMD CPU, but it’s typically virtualized and shared by many isolated programs running on the same hardware. Crucially, there is no GPU on this commodity server. This means that all of Chromium’s client-oriented rendering optimizations are unavailable.
It’s possible to get a server with a GPU, but these computers are nothing like the simple smartphone or laptop for which Chromium is optimized. GPU servers are designed for the massive number crunching required by machine learning and AI applications. These special GPUs can cost tens of thousands of dollars and they include large amounts of expensive VRAM. All this special hardware goes largely unused if you use such a GPU to render CSS effects and some video layers that a Chromebook could handle.
At the moment of this writing, the situation is even worse because these GPU servers happen to be the hottest commodity in the entire tech industry. Everybody wants to do AI. The demand is so massive that Nvidia, the main provider of these chips, has taken an active role in picking which customers actually get access. This was reported by The Information:
Nvidia plays favorites with its newest, much-sought-after chips for artificial intelligence, steering them to small cloud providers who compete with the likes of Amazon Web Services and Google. Now Nvidia is also asking some of those small cloud providers for the names of their customers—and getting them—according to two people with direct knowledge.
It's reasonable that Nvidia would want to know who’s using its chips. But the unusual move also could allow it to play favorites among AI startups to further its own business. It’s the latest sign that the chipmaker is asserting its dominance as the major supplier of graphics processing units, which are crucial for AI but in short supply.
In this situation, using server GPUs for web page recording would be like taking a private jet to go to work every morning. It’s technically possible, but you’d need an awfully good reason and some deep pockets.
There are ways to increase efficiency by packing multiple browser capture jobs on one GPU server. But you’d still be wasting most of the expensive hardware’s capabilities. Nvidia’s AI/ML GPUs are designed for high-VRAM computing jobs, not the browser’s GUI-oriented graphics tasks where memory access is relatively minimal.
Let’s think back to the private jet analogy. If you have a jet engine but your commute is only five city blocks, it doesn’t really help at all if you ask all your neighbors to join you on the plane trip — it’s still the wrong vehicle to get you to work. Similarly, with the server GPUs, there’s a fundamental mismatch between your needs and the hardware spec.
Why generic hardware needs specialized software
Is there a way we could render the web browser’s output on those commodity CPU-only servers instead? The problem here lies in the generic nature of the browser platform combined with the implicit assumptions of the commodity client hardware.
I noted above that capturing a web app ends up being “all or nothing” — a narrow subset of CSS is as good as useless. A browser automation system has more freedom here. It can execute on the CPU because it has great latitude for trade-offs across several dimensions of time and performance:
- When to take its screenshots
- How much rendering latency it tolerates
- Which expensive browser features to disable
In other words, browser automation can afford wait states and it can skip animations, but remote screen capture can’t. It must be real-time.
Fundamentally we have here a performance sinkhole created from combining two excessively generic systems. Server CPUs are a generic computing solution, not optimized for any particular application. The web browser is the most generic application platform available. Multiplying compromise by another compromise is like multiplying small fractions — the product is less than the individual components. Without any specialized acceleration on either the hardware or software side, we’re left in a situation where 30 frames per second on arbitrary user content remains an elusive dream.
Maybe we just use more CPU cores in the cloud? That’s a common solution, but it quickly becomes expensive, and it’s still susceptible to web content changes that kill performance.
For example, you can turn any DOM element within a web page into a 3D plane by adding perspective and rotateX CSS transform functions to it. Now your rendering pipeline suddenly has to figure out questions like texture sampling and edge antialiasing for this one layer. Even with many CPU cores, this will be a massive performance hit. And if you try to prevent web developers from using this feature, there’s always the next one. It becomes an endless whack-a-mole of CSS properties which will frustrate developers using your platform as the list of restrictions grows with everything they try.
Given that we can’t provide acceleration on the hardware side (those elusive server GPUs…), the other option left is to accelerate the software.
Designing for layered acceleration
At this point, let’s take another look at the hypothetical web app whose output we wanted to capture up above.
Within the UI area to be recorded, we can identify three different types of content. They are shown here in blue, pink, and green highlights:
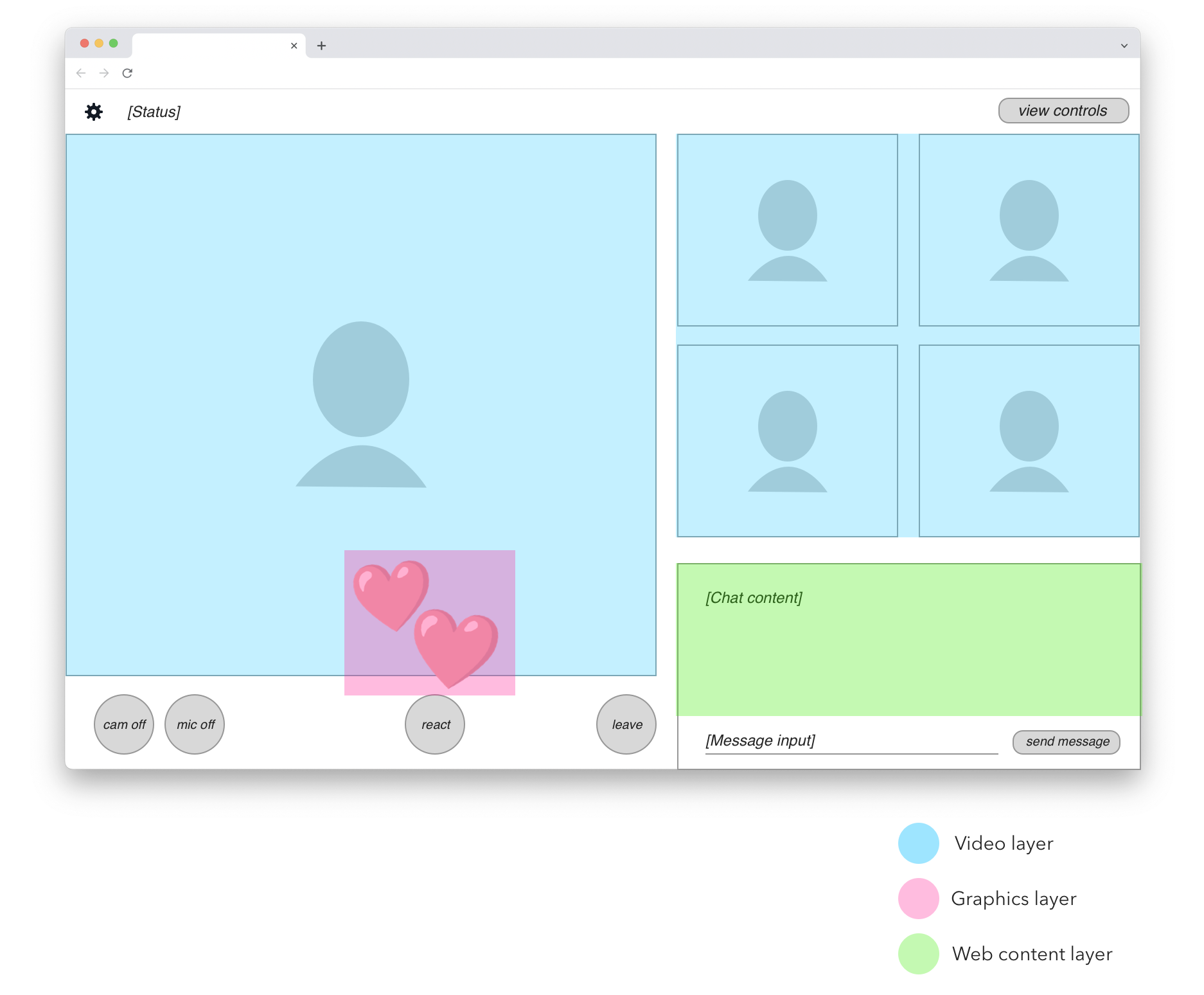
In blue we have participant videos. These are real-time video feeds decoded from data received over WebRTC.
In pink we have animated overlay graphics. In this simplified example, it’s only the emoji heart reactions. In a real application we would probably identify other graphical elements, such as labels or icons that are rendered on top of participant videos.
In green we have the shared chat view. This is a good example of web content that doesn’t require full 30 fps screen capture to be rendered satisfactorily. The chat view only updates every second at most, is not real-time latency sensitive, and doesn’t depend on CSS animations, video playback, or fancy WebGL. We can render this content on a much more limited browser engine than what’s required for complete web page recording.
Identifying these layers is key to unlocking the software-side acceleration I mentioned earlier. If we could split each of these three content types onto separate rendering paths and put them together at the last moment, we could optimize the three paths separately for reasonable performance on commodity servers.
The accelerated engine
Could we do this by modifying the web browser itself? Forking Chromium would be a massive development effort and we’d be scrambling to keep up with updates. But more fundamentally, technologies like CSS are simply too good at enabling developers to make tiny code changes that will completely break any acceleration path we can devise.
At Daily, we provide a solution in the form of VCS, the Video Component System. It’s a “front-end adjacent” platform that adopts techniques of modern web development, but is explicitly designed for this kind of layered acceleration.
With VCS, you can create React-based applications using a set of built-in components that always fall on the right acceleration path. For example, video layers in VCS are guaranteed to be composited together in their original video-specific color space, unlocking higher quality and guaranteed performance. There's no way a developer can accidentally introduce an unwanted color space conversion.
For content like the green-highlighted chat box in the previous illustration, VCS includes a WebFrame component that lets you embed arbitrary web pages inside the composition, very much like an HTML <iframe>. It can be scaled individually and remote-controlled with keyboard events. This way you can reuse dynamic parts of your existing web app within a VCS composition without wrecking the acceleration benefits for video and graphics.
VCS is available on Daily’s cloud for server-side rendering of recordings and live streams. With the acceleration-centric design, we can offer VCS as an integral part of our infrastructure, available for any and all recordings. It’s not a separately siloed service with complex pricing. That means you always save money, and we can guarantee that it will scale even if your needs grow quickly.
This post has more technical detail on how you might implement a layered web page recording on VCS. Look under the heading “Live WebFrame backgrounds”.
One more thing to consider… The benefits of layered acceleration can be more widely useful than just for servers. If you can structure your application UI this way, why not run the same code on clients too? For that purpose, we offer a VCS web renderer that can be embedded into any web app regardless of what framework you’re using. This lets you isolate performance-intensive video rendering into a managed “acceleration box” and focus on building the truly client-specific UI parts that are not shared with server-side rendering.
For a practical example of how to use the VCS web renderer, see the Daily Studio sample application. It’s a complete solution for Interactive Live Streaming where the same content can be rendered on clients or servers as needed.
Summary
In this post, we discussed the challenges and solutions to web page recording. Hardware acceleration is an expensive commodity, so Daily provides an alternative, more cost-effective solution in the form of our Video Component System which can include layered web content.
If you have any questions about VCS, don't hesitate to reach out to our support team or head over to our WebRTC community.
Never miss a story
Get the latest direct to your inbox.